ソフトウェアエンジニアの新田です。
これは カンム Advent Calendar 2024 の8日目の記事です。昨日はフロントエンドチームのEMの佐藤さんの記事 チームが成長するたびに変わっていった朝会の話 - カンムテックブログ でした。
私は現在プラットフォームチームに所属しており、おなじようにチームで朝会をしているので非常に参考になりました。積極的にパクっていこうと思います。
さて、カンムではプロダクトのデータベースに Amazon Aurora PostgreSQL を採用しています。
ここで少し特徴的なのは、このデータベースは、アプリケーションのデータ管理だけでなく、ジョブキューの役割も担っています。このジョブキューには、 Que の Go 実装である kanmu/qg (以下 qg )を使っています。
qg を用いることで、トランザクション 内でジョブをエンキューできるようになり、我々が主に開発しているカード決済などのプロダクトにおいて欠かせない、複数のサービス間のデータの整合性を効率的に担保しています。そのため、トランザクショナルなジョブキューは我々プロダクトの重要な技術基盤になっています。
この qg について説明した資料には以下のようなものがあります。
今回の記事は、この qg を用いたジョブキューの運用中に直面した、「デキュー時のパフォーマンス劣化」という問題についてお話しします。また、問題を正しく理解するために学んだ、 PostgreSQL の MVCC や Snapshot といった内部の仕組みについてもお話しします。
システムの概要
今回問題が起きたサービスのデータベースとワークロードについて説明します。
データベースは Aurora クラスタ です。クラスタ は、 writer インスタンス (読み書き) と reader インスタンス (読み取り専用) で構成されています。このデータベースを使った複数のワークロードが動作しています。
API ワークロード (以下 api )
モバイルアプリや外部システムからのリクエス トを受け付け、必要な処理を実行します。
Worker ワークロード (以下 worker)
非同期ジョブを処理する専用のワークロードです。これにより、リクエス ト処理とジョブ実行を分離し、効率的なリソース管理を実現しています。
ジョブは que_jobs テーブルで管理されており、ジョブのエンキューは que_jobs テーブルへのインサートになります。この操作は api と worker の両方から行われます。たとえば、api は外部リクエス トを受けた際にジョブをエンキューします。 worker は他のジョブをエンキューしたり、エラーになったジョブをリトライするために再度エンキューしたりします。
ジョブのデキューは worker が実行する必要のあるジョブのレコードを que_jobs テーブルから探します。このとき、 worker 同士が同じジョブを取得することを防ぐためにロックを獲得します。ここで、他の worker のクエリをブロックしないようロックを獲得する方法として pg_advisory_lock と Recursive CTE を組み合わせたアルゴリズム が用いられています。
worker は、ジョブ処理を正常に完了すると、 que_jobs テーブルから該当のレコードを削除します。
qg のロック獲得SQL
以下は、 qg がジョブをデキューする際に、ロックを獲得しながら1件のジョブを取得するための SQL です。
WITH RECURSIVE job AS (
SELECT (j).*, pg_try_advisory_lock((j).job_id) AS locked
FROM (
SELECT j
FROM que_jobs AS j
WHERE queue = $1 ::text
AND run_at <= now()
ORDER BY priority, run_at, job_id
LIMIT 1
) AS t1
UNION ALL (
SELECT (j).*, pg_try_advisory_lock((j).job_id) AS locked
FROM (
SELECT (
SELECT j
FROM que_jobs AS j
WHERE queue = $1 ::text
AND run_at <= now()
AND (priority, run_at, job_id) > (job.priority, job.run_at, job.job_id)
ORDER BY priority, run_at, job_id
LIMIT 1
) AS j
FROM job
WHERE NOT job.locked
LIMIT 1
) AS t1
)
)
SELECT queue, priority, run_at, job_id, job_class, args, error_count
FROM job
WHERE locked
LIMIT 1
このSQL がどのように動作するかをステップごとに説明します。
まず全体像として WITH RECURSIVE job AS ... とあるように Recursive CTE を構成しています。 Recursive CTE は、最初に評価される初期ステップと、以降繰り返し評価される再帰 ステップを UNION または UNION ALL オペレータで接続して構成されます。
それでは各部分の説明をしていきます。
初期ステップ
SELECT (j).*, pg_try_advisory_lock((j).job_id) AS locked
FROM (
SELECT j
FROM que_jobs AS j
WHERE queue = $1 ::text
AND run_at <= now()
ORDER BY priority, run_at, job_id
LIMIT 1
) AS t1
que_jobs テーブルから条件を満たすジョブを1件取得します。
このときに取得できたジョブの job_id に基づいて pg_try_advisory_lock を実行し、ロックを試みます。 pg_try_advisory_lock はロックを獲得できた場合は true を返し、すでに他のセッションにロックされている場合は false を返します。
UNION ALL (
SELECT (j).*, pg_try_advisory_lock((j).job_id) AS locked
FROM (
SELECT (
SELECT j
FROM que_jobs AS j
WHERE queue = $1 ::text
AND run_at <= now()
AND (priority, run_at, job_id) > (job.priority, job.run_at, job.job_id)
ORDER BY priority, run_at, job_id
LIMIT 1
) AS j
FROM job
WHERE NOT job.locked
LIMIT 1
) AS t1
)
初期ステップでロックを獲得できなかった場合 (WHERE NOT job.locked )、次のジョブを探索してロックを試みます。このときに初期ステップで取得したジョブよりも後に位置するジョブを探索範囲とし、優先度の高い (qg では priory の値が低いほど優先度は高い) ジョブを1件取得します。条件に合うジョブがあれば pg_try_advisory_lock でロックを試みます。
結果の選択
SELECT queue, priority, run_at, job_id, job_class, args, error_count
FROM job
WHERE locked
LIMIT 1
再起的に探索したジョブの中から、ロックに成功した1件を取得します。
このようにして、 pg_try_advisory_lock によるロック試行を行うことで、複数の worker が同じジョブを処理することを防いでいます。
発生した問題について
qg のパフォーマンス悪化
日々の運用では、未処理ジョブが滞留せずに処理されているかを DataDog でモニタリングしています。ある日、大量のジョブが滞留したまま消化できていない状況が発生し、アラートが鳴りました。
調査したところ、大量のジョブ自体は毎日ほぼ同じ時間にエンキューされるもので、普段の投入量と大きな変化はありません。しかし、普段と比較して worker がジョブのデキューして処理する時間が著しく長くなっていました。
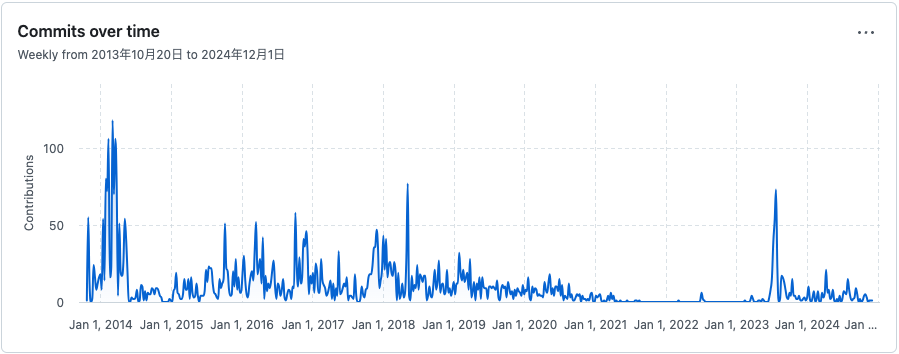
worker のログを確認したところ、ジョブ取得処理の時間 (lock_time) が通常よりも長くなっていることが判明しました。さらに、 DataDog で監視している dead tuples のメトリクス (postgresql.dead_rows ) を確認したところ、 que_jobs テーブルの dead tuples が増え続けていることがわかりました。
とある時間帯から増え続ける dead tuples
dead tuples とは、 PostgreSQL において更新や削除操作によって古くなり不要となったレコードです(内部的には「タプル」と呼ばれます)。これらのタプルは即座に削除されるわけではなく、 VACUUM によってクリーンアップされます。
この dead tuples の増加が原因で、 qg のパフォーマンスが劣化することは既知の問題として把握していました。 詳細については以下の文献が非常に参考になりますが、本記事でも後ほど PostgreSQL の内部構造を踏まえて解説します。
原因の特定
さて、この状況を改善するには、 VACUUM による dead tuples の回収が必要です。本来、 autovacuum がこれを自動的に処理するはずですが、どうやら適切に機能していないようでした。
ここで、 pg_stat_acitivity を用いてアクティブなクエリを確認したところ、意図していないクエリが発行されていることが判明しました。 (後になって気づいたのですが、このクエリは Performance Insights でも目立つ形で表示されていました。当時は余裕がなく見落としていましたが、こうした状況ではどこを確認すべきかを形式化・習慣化する必要があると感じました…)
意図していないのは、そのクエリのユーザ (postgreSQL の user) です。それは社内で利用している BI ツール Redash 用に作成されたユーザでした。本来、 Redash からは reader インスタンス に向けてクエリを実行することを意図していましたが、過去に筆者が Aurora データベースを Redash に新しいデータソースとして登録する際に、誤ってクラスタ エンドポイント(writer インスタンス を指す)を参照してしまっていたことが原因でした。正しくは reader エンドポイント (reader インスタンス を指す) を設定する必要があります。この設定ミスを修正し、 reader エンドポイントを指すように変更しました。
該当のクエリは、 Redash クライアントとの接続がすでに切れているにもかかわらず、 pg_stat_activity で観測され続けていました。このクエリの wait_event は io:BufFileWrite となっていました。このクエリは、大量のテーブルスキャンと CTE を組み合わせる、まさにデータ分析のためのアドホック なクエリで、非常に重い処理でした。
さらに、あろうことか、このクエリのユーザの設定には statement_timeout などのクエリタイムアウト の設定をしていなかったため、クライアント接続が切れても PostgreSQL のバックエンドプロセス自体はクエリの処理を続行していました。
問題の解消までの流れ
以下は、問題発生時に手動で実行した VACUUM のログです。 (VACUUM VERBOSE que_jobs というSQL を実行):
INFO: vacuuming " service_x.que_jobs "
INFO: " que_jobs " : found 0 removable, 768195 nonremovable row versions in 15623 out of 15623 pages
DETAIL: 679473 dead row versions cannot be removed yet, oldest xmin: 1226078887
There were 1005 unused item identifiers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user : 0 .08 s, system: 0 .00 s, elapsed: 0 .08 s.
0 removable とは削除可能な(不要とみなせる)タプルは0件であることを表しています。これは VACUUM で削除できる dead tuples が存在しないことを示しています。
768195 nonremovable row versions とは削除できないタプルが 768,195 件存在することを表しています。多くの行が nonremovable である原因は、これらがまだ参照されているためです (後述する oldest xmin と関連します)。 in 15623 out of 15623 pages はこのテーブルの全ページ(15,623ページ)がスキャンされたことを示します。
679473 dead row versions cannot be removed yet は、 679,473件の dead tuples が削除不能 な状態にあります。これらタプルは他のクエリが参照できる状態にあるため削除できないのです。
そして oldest xmin: 1226078887 が、アクティブなクエリのなかで、最も古い xmin のスナップショットを保持するクエリが保持する xmin を示しています。
このログから読み取れることは以下です。
大量の dead tuples が削除不能 に陥ってる
679,473件の dead tuples が削除できず、 que_jobs テーブルの肥大化を引き起こしています。
VACUUM が効いていない
削除可能なタプルが 0 件であるため、 VACUUM を実行しても que_jobs の dead tuples は回収されず、 qg のパフォーマンスは改善されないままです。
このログの oldest xmin が指し示す xmin 1226078887 を保持するクエリこそ、まさに pg_stat_activity で見つけていたクエリでした。これは pg_stat_activity のカラム backend_xmin の値も 1226078887 と一致していました。
VACUUM を阻むクエリであることを確信したので、 pg_terminate_backend を実行して当該クエリのプロセスを強制的に終了させました。プロセス終了を確認後、再度 VACUUM を手動で実行したところ、今度は大量に dead tuples をクリーンアップしてくれました。
一気に回収される dead tuples
そして、 worker のデキューのパフォーマンスは無事正常状態に戻りました。
ここまでが当時発生した問題の原因の特定から解消までのオペレーションの流れになります。
que_jobs テーブルとは全く関係のないクエリであっても、おなじ DB インスタンス 上で長時間実行されることで、 que_jobs テーブルの dead tuples を回収できずにテーブルを肥大化させ続け、結果的に qg のデキューパフォーマンスや DB の負荷上昇につながってしまっていました。
再発防止のための対策
この反省を踏まえて、以下の対策を進めています。
Redash で writer エンドポイントを指定しても writer インスタンス に接続できないようにする。
今回の問題は Redash が writer インスタンス に向けてしまった設定ミスから始まりました。
そこで、プラットフォームチームの菅原さんが Redash コンテナの /etc/hosts を書き換えるアイデア で対応してくれました。 writer エンドポイントのホスト名に対応するIPアドレス をテスト用の無効なIPアドレス (TEST-NET-1) を指定することで、誤って writer エンドポイントを設定したとしても実際に接続することはできないようになります。
PostgreSQL ユーザの statement_timeout を設定する。
今回、クエリにタイムアウト 設定がなかったため、長時間クエリが残り続けました。 PostgreSQL の statement_timeout を適切に設定し、長時間クエリを自動的に停止するようにして再発を防ぎます。
デキューアルゴリズム の改善
上述した文献にも紹介されるように、現在の qg では qg_advisory_lock と Recursive CTE を使用していますが、これらは dead tuples に影響を受けやすい設計です。
たとえば比較的新しい PostgreSQL ジョブキュー実装である https://github.com/riverqueue/river では、より新しいロック獲得方法の SELECT FOR UPDATE SKIP LOCKED を利用するなどといった効率的な方法が採用されています。
今後のサービスの拡大に伴い扱うジョブの増加に耐えられるよう、 qg の改善もしくは river のような技術の採用を検討していきたいと考えています。
今回取り上げた問題は、 実行時間の長いクエリによって VACUUM が効果を発揮しない 、PostgreSQL データベース運用の典型的なケースです。恥ずかしながら、今回の問題をきっかけに、自分の知識不足を痛感しました。
問題の根本原因を深く理解するため、改めて PostgreSQL の内部構造に目を向け、 MVCC (Multi-Version Concurrency Control) や Snapshot といった仕組みを基礎から見直しました。それに加えて、 VACUUM や dead tuples が何を意味しているのか、我々のプロダクトの運用に対しどのように影響を与えるのかを理解することに努めました。
オススメの資料
この記事でもこのあと説明しますが、以下の資料は PostgreSQL のトランザクション 、MVCC、スナップショットなどをわかりやすく丁寧に説明しています。ぜひ読んでいただくことをおすすめします。
MVCC を実現するタプルの xmin, xmax
PostgreSQL では一貫性を保ちながら複数トランザクション の平行処理を効率化する仕組みとして MVCC (Multi-Version Concurrency Control) を採用しています。
DELETE の SQL が実行されても、実際に削除対象であるタプルをその場で削除することはなく、削除マークを付け加えるだけです。 UPDATE の場合は、削除マークを付け加え、更新後の値を保持する新しいタプルを作成します。
とあるトランザクション が DELETE しても、そのトランザクション が COMMIT されるまでのあいだ、他の進行中のトランザクション からすればそのタプルはまだ使用可能である必要があるためです。
各タプルは、データそのものとメタデータ (タプルヘッダ)を持っています。このヘッダに格納されている xmin, xmax が、タプルの可視性を判定する基盤となっています。
INSERT 時にセットされるのが xmin です。
DELETE 時にセットされるのが xmax です。
UPDATE では、既存タプルの xmax に値をセットし、新しいタプルに xmin に値をセットします。
xmax が設定されているものこそが、更新や削除により不要となったタプル、 dead tuple です。
スナップショット
スナップショットは、クエリが「どのデータを可視とするか」を決定するためのデータ構造です。
スナップショットの実態は SnapshotData という構造体です (code )。いろんなメンバがありますが、今回取り上げたいのは xmin, xmax, 進行中のトランザクション の配列 xip です。
typedef struct SnapshotData
{
TransactionId xmin;
TransactionId xmax;
TransactionId *xip;
} SnapshotData;
スナップショットのこれらのメンバは可視性判定時に以下のように振る舞います。
具体例を用いて説明します。以下のテーブル fruit に3つのタプルがあるとします。
name
xmin
xmax
apple 101
105
banana
102
null
cherry
104
null
apple タプル
banana タプル
cherry タプル
ここで、進行中のトランザクション が2つあるとします。 (XID=104, XID=105)
このとき、 XID=103 のトランザクション 上で以下のスナップショットが作成されたと考えます。
xmin=103xmax=106xip=[104, 105]
このスナップショット情報とタプルの情報を突き合わせることで、このスナップショットからのタプルの可視性を判定できます。
apple タプル (xmin=101, xmax=105)
xmin=101 : XID < 103 のため挿入は完了している。
xmax=105 : 進行中のトランザクション のため、削除はこのスナップショットからは見えない。
結果 : 可視
banana タプル (xmin=102, xmax=nulll)
xmin=102 : XID < 103 のため挿入は完了している。
xmax=null : どのトランザクション からも削除されていない。
結果 : 可視
cherry タプル (xmin=104, xmax=nulll)
xmin=104 : 進行中のトランザクション のため、挿入はこのスナップショットからは見えない。
結果 : 不可視
このようにして、タプルのメタデータ である xmin と xmax とスナップショットの xmin と xmax を用いた「可視性」の判定によって、 PostgreSQL はトランザクション ごとに一貫性のあるデータビューを提供していることがわかります。
スナップショット作成のタイミング
弊社の PostgreSQL データベースでは、トランザクション 分離レベルを READ COMMITTED に設定しています。この場合、トランザクション ではないクエリにおいても、クエリを実行する際にスナップショットを作成します
この説明が正しいか実際の PostgreSQL のソースコード を確認してみます。
SQL を処理する exec_simple_query() の中では、すべてのクエリで GetTransactionSnapshot() が呼び出されます。この関数内では、現在のトランザクション 分離レベルに応じて動作が異なります。
READ COMMITTED の場合
各クエリで常に新しいスナップショットを作成するため、GetSnapshotData() が毎回呼び出されます。
REPEATABLE READ の場合
最初のスナップショットを取得した後は、それをキャッシュして再利用します。
この仕組みによってトランザクション の分離レベルに応じたスナップショット管理が実現されていることがわかります。
https://github.com/postgres/postgres/blob/792b2c7e6d926e61e8ff3b33d3e22d7d74e7a437/src/backend/utils/time/snapmgr.c#L280
VACUUM が dead tuples を回収できなかった理由
Redash から実行されたクエリは、スナップショットをその時点で作成し (READ COMMITTED) 、それ以降に作成された que_jobs テーブルのタプルがたとえ DELETE で削除されていても、そのクエリからは可視であったためでした。
よって、 VACUUM は que_jobs テーブルの多くのタプルは Redash から実行されたクエリにとって可視であることを理由にタプルのクリーンアップをしない判断をとっていたのです。
qg のクエリパフォーマンスへの影響
タプルの xmin, xmax はタプルのヘッダ上に含まれています。つまり、タプルが live なのか dead なのかを確認するためにはタプルにデータアクセスする必要があります。インデックス自体にはタプルの可視性といった情報は保持されていません。
qg のロック獲得SQL を振り返ってみると、 WHERE 句で絞る条件には queue と run_at しか用いられていません。
WHERE queue = $1 ::text
AND run_at <= now()
そのため、それらの条件を満たすが既に dead であるレコードに対してもインデックスの走査対象となり、可視性の確認のために都度タプルをフェッチする非効率なことが行われているのです。
まとめ
以上、この記事では、 PostgreSQL を用いたジョブキュー qg の運用において発生したデキューパフォーマンス問題を題材に、問題解決の過程、および得られた学びについて共有させていただきました。
具体的には、 VACUUM が dead tuples を回収できなかった原因を MVCC やスナップショットの仕組みに基づいて解析し、 dead tuples の増加に伴いデキューパフォーマンスが劣化する原因を可視性の判定にタプルのフェッチが必要となるオーバーヘッドの観点から説明しました。
この問題を通じて、運用上のいろいろな教訓や学びを得ることができました。今後もプロダクトの成長とともにこのジョブキュー基盤の利用は多くなってくるので、改善を重ねて信頼性の高い基盤づくりをしていきたいと思います。
この記事がどなたかの役に立てば幸いです。
カンムではバックエンドエンジニアを募集しています。ご興味ある方はぜひご連絡ください!
team.kanmu.co.jp