こんにちは。ソフトウェアエンジニアの新田です。こちらは カンム Advent Calendar 2023、8日目の記事です。 昨日はデザイナー torimizuno さんによる バンドルカードの Google Pay デザイン でした。今年のバンドルカードの目玉リリースの1つであるスマホタッチ決済(Google Pay)のデザインについて説明されていて、凄く面白いです。
今回は、カンムの機械学習のインフラ周りについて話します。実はカンムのテックブログでは2年半前に同じテーマの記事があります。この内容からいくつかアップデートがあるので、今回はその差分を重点的に拾っていこうと思います。
また、自分は入社してそろそろ一周年で、前回の記事は入社前に読んでいました。今回の記事では、入社前ではわからなかったところもあえて注目して取り上げてみたいなと思います。
Big Picture

Data Preparation
BigQuery データウェアハウスの刷新
クラウドの構成は以前同様、プロダクトは AWS をメインに使いつつ、データ基盤は Google Cloud の BigQuery に集約する構成は一緒です。しかし BigQuery 基盤自体は以前と違うものになっています。
これまでのカンムのデータ分析環境では、本番環境の DB からレプリケーションしている分析用のリードレプリカを利用していました。一方で、データベースは複数存在しているため、リードレプリカを利用した環境では複数データベースをまたいだデータ分析が難しいという課題がありました。
そこで複数のデータソースを一つの BigQuery によるデータウェアハウスに集約することを念頭において基盤を再構築しました。これによって複数のデータソースを横断した分析ができ、事業KPI をより精緻なかたちで算出できるようになるなど、データによる意思決定の精度が上がっています。
例に漏れず機械学習の学習データセットも、この新しい BigQuery 基盤を使うように変更しています。
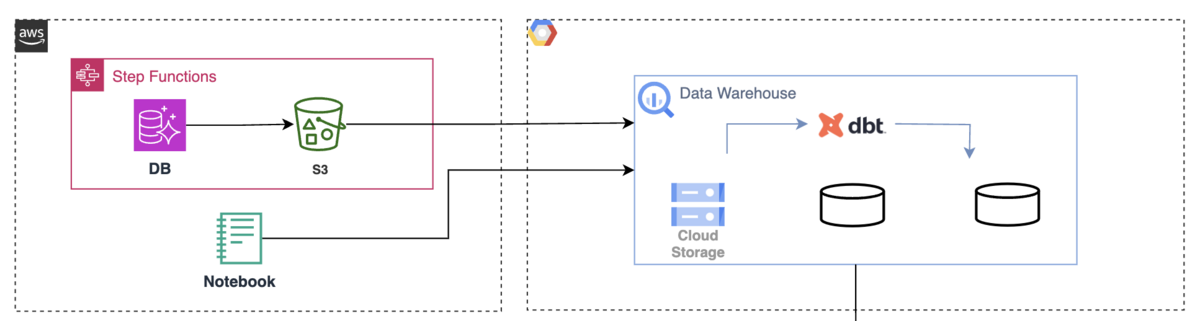
以前の構成では Embulk を利用していた BigQuery へのデータの取り込み周りも、新しい基盤では異なります。
カンムではプロダクトのデータベースは AWS Aurora を使っています。そこでエクスポート機能を使って S3 にデータをエクスポートします。
そのあと S3 から Google Cloud の Cloud Storage への転送を Storage Transfer Service で行います。
Cloud Storage に到着したデータを BigQuery の外部テーブルとして扱い、 BigQuery のテーブル・ビューとして整形するパイプラインを整備しています。
いわゆる Transform と呼ばれるこの一連のパイプラインは dbt を ECS Task として実行するような Step Functions で構成しています。 AWS から Google Cloud のリソースの認証には OIDC 方式を採用して鍵ファイルの管理を不要にしています。
このデータ取り込みにおいて、以前の構成の Embulk ではワークロードのリソース調達が必要になっていましたが、新しい構成では完全なマネージドなためその辺りの考慮が不要になったのは嬉しいポイントです。
以前同様、データ取り込みは差分更新ではなく全件洗い替えを日次実行しています。この辺はデータサイズ増加に伴うコスト面などの問題などがでてくると思うのでその際には改善を検討していきたいと思っています。
Training, Serving & Inference
推論モデルの増加
推論モデルは去年までは1つだったんですが、今では3つに増えました。
これまで学習データ不足などから機械学習でアプローチできていなかった課題に対しても、機械学習の推論モデルを徐々に導入できています。
いまのところ全てのモデルにおいて、同じアルゴリズムをベースに学習しています。
1つのリポジトリにて、ライブラリやウェブフレームワーク・ Web サーバ構成などは共通しており、デプロイパッケージは1つのコンテナイメージとして管理しています。
コンテナ実行時に環境変数を渡すことで実行する学習コードや推論コードが切り替わるようにしています。これによりモデルの数が増えてもロジック以外のセットアップが少なく完結できます。
これは利用するアルゴリズムを限定するつもりではなく、いまは1つのアルゴリズムで間に合っているためであり、新たなアルゴリズムが必要になったらその時々に拡張していければいいなという考えです。
推論モデルのデリバリー改善
以前と変わらず、モデルの学習から検証用のエンドポイントへの適用までを Step Functions によって自動化しています。
そのあとのモデルの性能やエンドポイントの動作に問題がないか確認をしたのちに、本番用のエンドポイントに適用する流れも同じです。ただ、この辺の作業が以前までは手動で行われていたのですが、運用するモデルが増加するにあたってこの手作業はトイルになってしまうので自動化しました。
自動化のために2つの GitHub Actions のワークフローを用意しています。
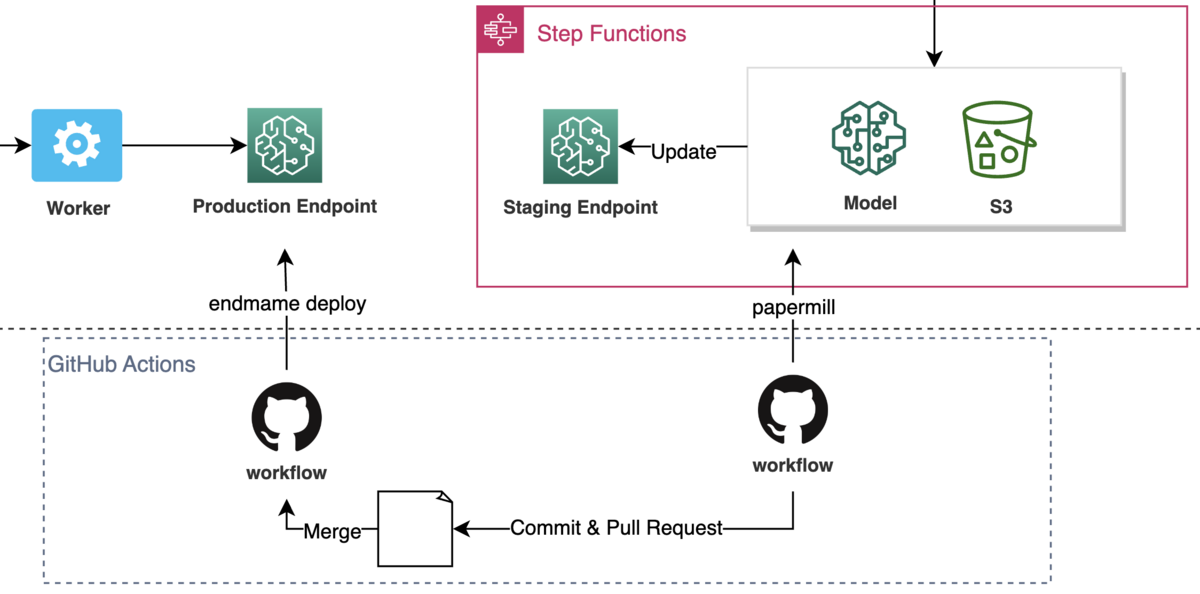
1つ目のワークフロー(図右) はモデルの性能結果を示す Pull Request を作成します。それをチームメンバー達でレビューしマージします。 マージを契機に、 2つ目のワークフロー(図左) が本番エンドポイントに EndpointConfig を適用します。これにより新しいモデルが本番にデプロイされます。
endmame によるデプロイ
2つ目のワークフローはデプロイに endmame という内製の CLI ツールを使って endmame deploy コマンドでデプロイを実行します。 ( えんどまめ と読みます。カンムでお世話になっている ecspresso や lambroll をリスペクトしています。)
この endmame のコマンド endmame deploy は、設定ファイルを読み込み、新しい EndpointConfig を適用するかたちで、対象の SageMaker Endpoint に更新します。 (sagemaker:UpdateEndpoint をコールし、デプロイが完了するまで sagemaker:DescribeEndpoint で状態をポーリングします。)
処理の流れ
1つ目のワークフローの実行
まず1つ目のワークフロー (図右) はあらかじめ用意した Jupyter Notebook のファイルを papermill を使ってバッチ実行し Pull Request の作成までを行います。
Jupyter Notebook はセルを順番に実行すると以下の処理が実行されるようになっています。 papermill をとおしてそれらの処理を GitHub Actions 上で実行します。
- 検証用エンドポイントからモデルの情報を取得し、それから学習結果のログやメトリクスを取得する
- 学習結果のログ、メトリクスの内容をセルに出力する
- 検証用エンドポイントにテストデータを用いて実際にリクエストしレスポンス内容をセルに出力する
- 本番エンドポイントの設定に対応している endmame の設定ファイルを編集する
このワークフローは上流の Step Functions の処理の完了時間からバッファを持たせて GitHub Actions の on.schedule によって自動で実行されるようにしています。また、開発者が任意のタイミングで実行できるように on.workflow_dispatch による手動実行も可能にしています。
このワークフローは以下の処理を行います。
- 上述の Jupyter Notebook を papermill によってコピー & 実行
- リポジトリをチェックアウトし新規ブランチを作成
- 新規に作成されたコピー先の Notebook ファイル と 変更された endmame 設定ファイル をコミット
- Pull Request を作成
つまりこの Pull Request のコミット内容は、検証エンドポイントにデプロイされた新しいモデルの性能評価結果および API サーバの動作検証結果がレポートされた Notebook ファイルの追加コミットと、本番エンドポイントに適用する予定の設定ファイルの変更コミットになります。
作成された Pull Request のレビュー・マージ
モデル開発チームはその自動作成された Pull Request の内容 ( Notebook の内容と設定ファイルの変更内容) を確認し、問題なければ承認しマージします。
2つ目のワークフローの実行
マージを契機に2つ目のワークフロー(図左)が動作します。
endmame deploy コマンドを実行して、 Pull Request で変更された設定ファイルを読み込んで実際に本番エンドポイントを更新します。
このワークフローの実行が完了したらデプロイの成否が Slack に通知されるようにしています。
ちなみにですが、1つ目のワークフロー上で、デフォルトの GITHUB_TOKEN によるユーザとして Pull Request を作成してしまうと、その Pull Request 上で GitHub Actions の CI が回らないので注意が必要です。
解決策として GitHub App のインストールとして認証を行い git push や Pull Request 作成の操作等を行うようにしています。
- GitHub App インストールとしての認証 - GitHub Docs
- GitHub - actions/create-github-app-token: GitHub Action for creating a GitHub App Installation Access Token
自動化の意図
デリバリープロセスの自動化の意図は「モデルが増えてきた作業時間の増加を短縮したいから」「モデル自体を入れ替えないタイプの変更 (ライブラリのアップデート) なども素早く安全にやりたいから」「強力な権限による手動操作の排除」etc… などがありますが、それに加えて、データセットシフトなどの問題に対する推論モデルのロバスト性を高めるために、性能評価プロセスをより高度なものにしていきたいと考えているためです。
そこで、あらかじめプロセスを自動化しておくと今後のプロセス改善はラクになります。今回構築したフローでは、テンプレートの Notebook ファイルを編集するだけで、それ以降の実行に反映されます。作業手順書のメンテナンスの必要がなくなりますし、手順を誤ると起きてしまうヒューマンエラーを防いでくれます。
評価プロセスの改善は今後力を入れていきたい領域の一つであるため、アップデートがあればまた記事にできたらいいなと思っています。
推論処理の課題
全てのモデルの推論処理は、「モデルをメモリにロードしておき、リクエストを受け付けると推論処理の結果を返すサーバを稼働するアーキテクチャ」 (リアルタイム/オンライン推論サーバ)になっています。
つまりオンライン処理時点で入力特徴量の取得が必要になります。 現状では、呼び出し側のサービスがデータベースからデータを取得・計算して入力特徴量を組み立てて、推論エンドポイントにリクエストを投げています。
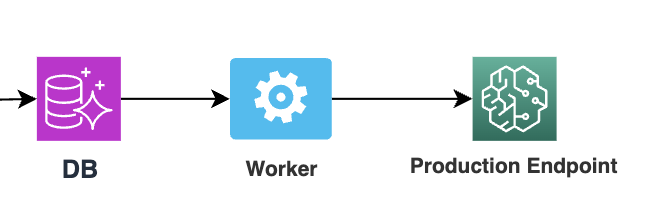
図をみて勘の良い方はお気づきかもしれませんが、学習時と推論時に異なるデータソースを用いているため計算の再現性に気を付ける必要があります。モデルの数や特徴量の増減のたびにこの辺りに慎重な実装を要していることや、学習に利用するデータソースの種類を増やした場合に推論時はそれをどのように取得するか… などの考慮事項があり、色々と課題が表出しているため来期は取り組んでいきたい領域の一つです。
Development
ローカルマシンによる開発環境もありますが、重い計算をしたい場合もっと大きなインスタンスが欲しくなるという要望を受け、クラウド上で開発できる環境を整備しています。
SageMaker Studio を使った JupyterLab ベースの実験環境です。いくつか工夫して使っていて、アイドルインスタンスを自動停止する仕組み、 OIDC 連携の仕組み、デバイスフローで GitHub App のユーザアクセストークンを発行してプライベートのリポジトリを操作する仕組み… などです。
実は今回の記事は本当はその辺りの話を書きたかったんですが、この記事の一週間前に SageMaker Studio に大幅なアップデート がアナウンスされて、これまでのものが SageMaker Studio Classic と名称が変更されました。あんまり Classic の話を書いてもな… と思って、今回の記事の内容を方針転換した経緯があります 😇
基本的に JupyterLab ベースの開発ですが、何時間単位となるような長時間の計算は JupyterLab は不向きな場合が多いためその辺りをシームレスにジョブ化できるような開発体験構築も検討していきたいと思っています。
- https://github.com/jupyterlab/jupyterlab/issues/2833
- https://github.com/jupyter-server/jupyter-scheduler
- https://docs.aws.amazon.com/sagemaker/latest/dg/notebook-auto-run.html
最後に
機械学習のインフラ周りについて、前回の記事からのアップデートを重点的に説明しました。
お察しの方もいらっしゃると思いますが、そこまでモダンな MLOps ! といった構成ではなく、必要なときに必要な自動化や改善をしてきて今のインフラになっています。途中途中で話しているように、まだまだやりたいけどやれてないことや課題などがあります。
入社してみて気づいたのですがカンムは情報の透明性が高いです。事業状況は事業計画が毎月アップデートされていたり、今後の事業方針について役員・ディレクター陣からの説明も随時行われます。
これまでに書いたようにまだまだ課題が山積みなので、事業状況にアクセスできる環境は、計画から先んじて必要な仕組みは何かを考えて次の打ち手を検討するときに非常にありがたいです。
この辺りの課題に向き合って楽しく議論しながら一緒に働いてくれるお仲間を募集しています。