エンジニアの佐野です。今日はカンムの決済システムでユーザの残高管理をどうやっているかについて書きます。
カンムの製品であるバンドルカードはプリペイド方式のカードです。ユーザによる入金、店舗での利用、運営事由の操作などによりユーザの残高が増減します。このような残高の管理について単純に考えると user_id と balance と updated_at あたりをもったテーブルを用意して balance と updated_at を更新していく方法があるかもしれません。しかしながらカンムでは残高を管理するテーブルを持たず、これらイベントの履歴のみで残高を管理しています。以下、本記事ではこれらユーザの残高が増減するイベントのことをトランザクションと呼びます。ここでは DB の Transaction Processing を意味しません。
本記事のポイントは
- 残高を管理をするテーブルは作らず、トランザクション履歴のsumで都度残高を算出している
- そのクエリは遅くなるのでは?とよく言われますがそんなことはない、雰囲気で判断するのではなく実行計画とベンチマークで判断しましょう
- とはいいつつデータ量が増えたときの戦略を考案しておきましょう
です。想定読者は DB の論理設計を行う人間です。
- 前提知識
- トランザクション周りのDB設計
- 残高算出のクエリとその実行計画
- データ量が増えたときの戦略
- まとめ
の順で話していきます。
1. 前提知識
業務用語や専門用語が出てくるため、まずは読んでもらうための前提知識をいくつか説明します。
- トランザクションの種類
- オーソリとクリアリング
- Available Balance と Ledger Balance という2つの残高の概念
冒頭で述べた通り、入金、決済などユーザの残高が動くイベントをここではトランザクションと呼びます。業務上、トランザクションは5つの種別に分けています。
- 入金
- ユーザがバンドルカードに入金するときに発生します。
- 残高を加算します。
- 手数料徴収
- 手数料です。例えばバンドルカードに会員登録をするとECサイトなどで使えるバーチャルカードが手に入ります。実店舗で使いたい場合はリアルカードを申請していただく必要があります。現在リアルカード申請時にはいくらか手数料をいただいており、その申請時に発生します。
- 残高を減算します。
- 運営事由
- 運営判断によりユーザの残高を増減させることがあります。例えば退会時、インセンティブの付与時など。
- 残高を加算することもありますが減算することもあります。
- オーソリ
- 買い物をすると実店舗/ECサイトなどからカード番号や有効期限に加えて決済金額が飛んできます。それらの情報を使ってカンムのシステムは決済可能かどうかを判断します。Authorization / 仮売り上げ / 与信と呼ばれたりします。
- 残高を減算します。返品されたときは加算することもあります。
- クリアリング
- オーソリで決済OKになったものについて、後日店舗から確定伝票が送信されます。これが届くとカンムのシステムは対応するオーソリを探して、その金額を「確定」とします。Clearing / 実売り上げと呼ばれたりします。
- オーソリで減算または加算した残高をさらに減算または加算することがあります。どういうことだ?と感じると思うので次節オーソリとクリアリングで説明します。
1.2. オーソリとクリアリング
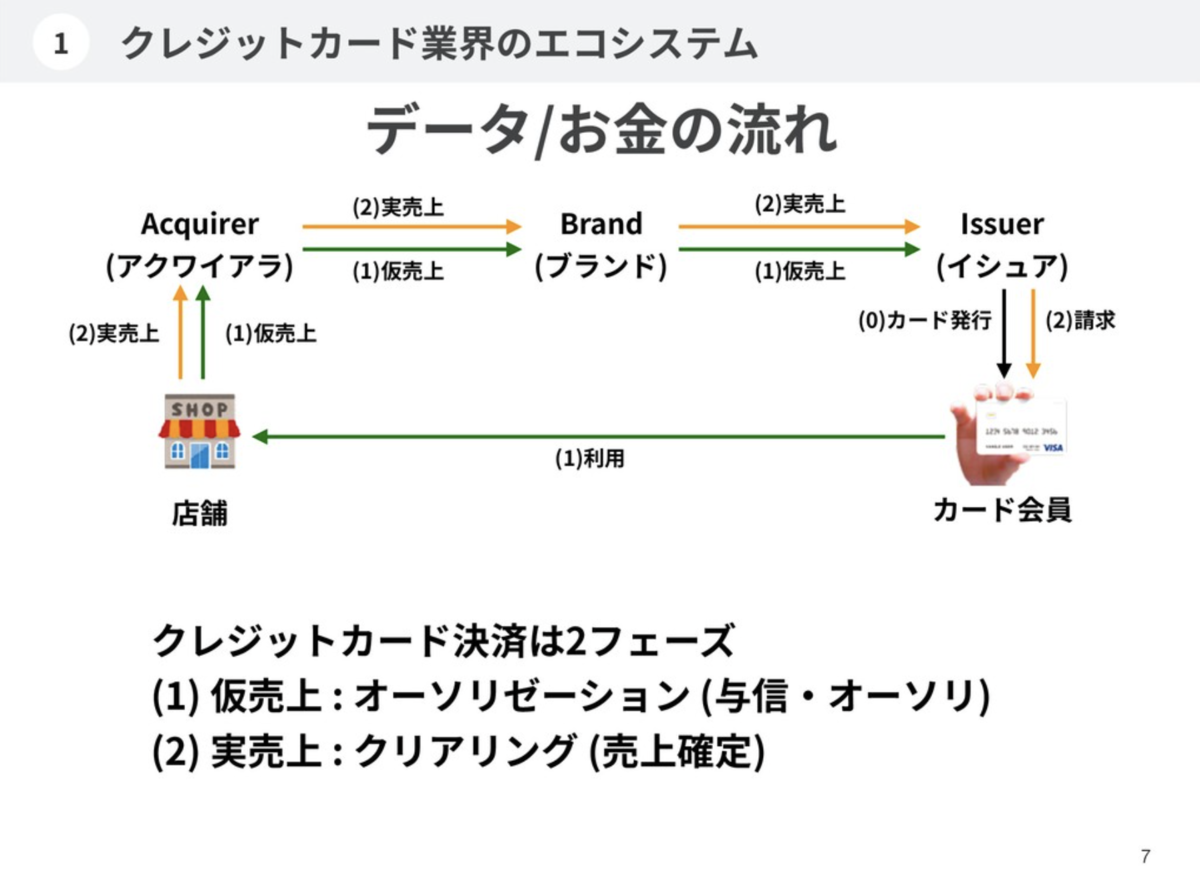
こちらの図は筆者が2年前に書いたものなのですが、この図の通りカード決済は2フェーズに分かれています。店舗で決済を行うとまずはオーソリが飛んできて残高が引かれますが、このオーソリの金額は仮の金額として扱われます(フェーズ1)。そして後日飛んでくるクリアリングの金額が実際の決済金額として扱われます(フェーズ2)。店舗での決済金額が仮で、後日改めて飛んでくるものが実際の金額とはどういうことだ?店舗で買ったときの値段=実売り上げではないのか?と思うかもしれません。その通り、ほとんどの場合において店舗での決済金額である仮売り上げと、実売り上げの金額はイコールになります。
しかしながらいくつかのケースにおいては仮売り上げと実売り上げで金額が異なる場合があります。卑近な例でいうと海外で決済して為替変動の影響を受けた場合になります。ある日、1ドル100円のものを購入したとします。このときオーソリは100円です。後日1ドル101円になったとします。その日にクリアリングが発生すると101円になります。結果として100円の買い物をしましたが101円を請求されます。また、筆者がドッグフーディングをした結果ですが、海外のレストランでのチップの支払いはオーソリに入っていなくて、クリアリングに上乗せされてくるようでした。なぜ2フェーズに分かれているのかはカード業界の歴史の話になりますのでここでは割愛しますが、このような仕組みがあるため、オーソリとクリアリングで金額が異なることがあり、後発のクリアリングを正として残高の補正が行われます。
1.3. Available Balance と Ledger Balance という2つの残高の概念
最後の蘊蓄です。ここまでは残高の増減が発生するイベント、トランザクションについて説明しました。それらのトランザクションに従って残高という数字を単純に増減すれば良いのですが、カード決済には Available Balance(AB), Ledger Balance(LB) という2つの残高の概念があり、トランザクションによってどちらを増減するかを判断しなければなりません。
長くなってしまうので詳細は省きますが、仮の金額であるオーソリで増減するのが Available Balance, 確定金額であるクリアリングで増減するのが Ledger Balance だと思ってください。
以下、各種トランザクションが発生したときの Available Balance と Ledger Balance の動きの例を示します。
| Time |
Transaction |
Amount |
AB |
LB |
説明 |
| 2021/6/27 10:00 |
入金 |
+1000 |
1000 |
1000 |
まずバンドルカードを使うために1000円の入金を行う |
| 2021/6/27 11:00 |
リアルカード発行手数料 |
-600 |
400 |
400 |
リアルカード発行を申請、600円の申請手数料が引かれる |
| 2021/6/28 09:00 |
オーソリ |
-130 |
270 |
400 |
130円の買い物を行う |
| 2021/6/30 02:00 |
クリアリング |
-130 |
270 |
270 |
実売り上げが届き、130円として確定する |
入金(+1000円) -> リアルカード発行手数料(-600円) -> 130円の買い物(-130円) -> クリアリング (-130円)というトランザクションの発生と残高の推移を表しています。
ポイントとしては先ほど書いた通りオーソリでは基本的に Available Balance のみが引かれます。クリアリングでは Ledger Balance が引かれますが Available Balance が引かれることもあります。このケースでは仮売り上げ=実売り上げなのでLBのみが引かれています。クリアリングで Available Balance が変化するときは前節で説明した通り、オーソリと金額が異なるときになります。
さて、DB設計です。これらのトランザクションを管理する実際のテーブルを見てみます。
関連するテーブルのみを抜き出すと、load, charge_fee, admin_fund, authorization, clearing が存在します。これらテーブルは5つの種別に分けたトランザクションにそれぞれ対応しています。load は入金、charge_fee は手数料、admin_fund は運営事由の残高増減、authorization は オーソリ、 clearing は クリアリングです。
card_id, card_holder_id というカラムが見えますが、card_id はカード情報を管理する card への外部キー、ユーザに似た概念であるカード所持者を管理する card_holder への外部キーになります。誰のどのカードにどのトランザクションが発生したかの関連を持たせていることを意味します。card_holder_id にはインデックスが貼られています。authorization テーブルには card_holder_id と response_code の複合インデックスが貼られています。
Table "load"
Column | Type | Collation | Nullable | Default
----------------+--------------------------+-----------+----------+----------------------------------
id | bigint | | not null | nextval('load_id_seq'::regclass)
card_id | bigint | | not null |
card_holder_id | bigint | | not null |
amount | numeric | | not null |
loaded_at | timestamp with time zone | | not null |
load は amout に入金金額が入ります。入金した金額はAB/LB双方に作用するので入金トランザクションの金額は amount というカラムのみで管理します。
Table "charge_fee"
Column | Type | Collation | Nullable | Default
----------------+--------------------------+-----------+----------+----------------------------------------
id | bigint | | not null | nextval('charge_fee_id_seq'::regclass)
card_id | bigint | | not null |
card_holder_id | bigint | | not null |
amount | numeric | | not null |
collected_at | timestamp with time zone | | not null |
charge_fee は amout に手数料金額が入ります。こちらもAB/LB双方に作用するのでこちらのトランザクションの金額も amount というカラムのみで管理します。
Table "admin_fund"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+----------------------------------------
id | bigint | | not null | nextval('admin_fund_id_seq'::regclass)
card_id | bigint | | not null |
card_holder_id | bigint | | not null |
available_amount | numeric | | not null |
ledger_amount | numeric | | not null |
executed_at | timestamp with time zone | | not null |
admin_fund については柔軟性を持たせていて available_amount, ledger_amount 2つのカラムを用意して AB/LB にそれぞれ異なる金額を作用できるようにしてあります。
Table "authorization"
Column | Type | Collation | Nullable | Default
---------------------------------------+--------------------------+-----------+----------+----------------------------------------------
id | bigint | | not null | nextval('authorization_id_seq'::regclass)
card_id | bigint | | not null |
card_holder_id | bigint | | not null |
transaction_amount | numeric | | not null |
response_code | text | | not null |
received_at | timestamp with time zone | | not null |
オーソリは基本的には AB のみに作用するので金額は transaction_amount でのみ管理します。transaction_amount というカラム名はいろいろあってこうなっています(触れないでください)。オーソリは他のトランザクションと異なり、 OK/NG という概念が存在するため response_code というカラムをもっています。オーソリの失敗、成功を管理します。
Table "clearing"
Column | Type | Collation | Nullable | Default
-----------------------------------+--------------------------+-----------+----------+----------------------------------------------------
id | bigint | | not null | nextval('clearing_id_seq'::regclass)
card_id | bigint | | not null |
card_holder_id | bigint | | not null |
available_amount | numeric | | not null |
ledger_amount | numeric | | not null |
created_at | timestamp with time zone | | not null |
クリアリングは基本的にはLBに作用しますが、ABにも作用することがあるため available_amount, ledger_amount 2つのカラムを用意しています。
これらのテーブルには INSERT と SELECT しか行いません。各トランザクションが発生すると、トランザクション種別に応じたテーブルにひたすらデータを INSERT していきます。ユーザがアプリから見ることができる入金履歴や決済履歴、運営が管理画面から確認するユーザのトランザクション履歴はこれらのテーブルをすべて舐めて timestamp で order by しています。そして残高はこれらのテーブルの SUM を都度とることで表現します。
残高のみを管理するテーブルを用意しても良かったかもしれませんが、トランザクションの合算が残高の正解になるためわざわざ用意する必要がありません。正規化の観点からも計算可能な重複は DB からは省くべきなので教科書的には正しいです。またレビュー時に残高を更新しつつトランザクションをちゃんと INSERT しているか?などケアしなければならないポイントが増えます。これは経験則になってしまいますが、残高テーブルの数値とトランザクションの計算結果が合わない、などという事案が起きるかもしれません。
もちろん残高テーブルを単体で用意するメリットもあって、DB参照時にわかりやすい、トランザクションテーブルのSUMよりは確実に早いなどがあります。
このDBの設計を行ったときは全エンジニアで数日にわたって議論がなされました。議論の結果、トランザクションのSUMで良いとなったわけですがここではクエリのコストにフォーカスをあてて本当に遅いのか見てみます。
3. 残高算出のクエリとその実行計画
ではその残高計算のクエリはどうなっているでしょうか。実際のクエリは下記の通りです。
SELECT COALESCE(SUM(available), 0) AS available_balance
, COALESCE(SUM(ledger), 0) AS ledger_balance
FROM (
SELECT amount AS available, amount AS ledger
FROM load
WHERE card_holder_id = $1
UNION ALL
SELECT amount AS available, amount AS ledger
FROM charge_fee
WHERE card_holder_id = $1
UNION ALL
SELECT available_amount AS available, ledger_amount AS ledger
FROM admin_fund
WHERE card_holder_id = $1
UNION ALL
SELECT transaction_amount AS available, 0 AS ledger
FROM authorization
WHERE card_holder_id = $1 AND response_code = '00'
UNION ALL
SELECT available_amount AS available, ledger_amount AS ledger
FROM clearing
WHERE card_holder_id = $1
) AS _
すべてのトランザクションテーブルを card_holder_id でひっかけて、それぞれの金額を意味するカラムに別名をつけて UNION ALL して SUM をとります。
同じ商売をしているエンジニアの友人にもこのような設計とクエリについて話すと、遅そうだ、と言われます。ではここで実行計画を見てみます。本記事執筆時点で利用回数が多いユーザを card_holder_id に指定して、本番環境で実行計画をとった結果になります。
QUERY PLAN
Aggregate (cost=1709.56..1709.57 rows=1 width=64) (actual time=13.112..13.113 rows=1 loops=1)
-> Append (cost=0.43..1701.67 rows=526 width=64) (actual time=0.025..10.796 rows=7535 loops=1)
-> Index Scan using ix_load_card_holder_id on load (cost=0.43..124.50 rows=48 width=10) (actual time=0.024..0.250 rows=315 loops=1)
Index Cond: (card_holder_id = XXXX)
-> Index Scan using ix_charge_fee_card_holder_id on charge_fee (cost=0.42..9.81 rows=2 width=10) (actual time=0.008..0.012 rows=6 loops=1)
Index Cond: (card_holder_id = XXXX)
-> Index Scan using ix_admin_fund_card_holder_id on admin_fund (cost=0.42..12.07 rows=2 width=7) (actual time=0.007..0.023 rows=19 loops=1)
Index Cond: (card_holder_id = XXXX)
-> Subquery Scan on "*SELECT* 4" (cost=0.57..726.99 rows=214 width=36) (actual time=0.020..4.686 rows=3623 loops=1)
-> Index Scan using ix_authorization_card_holder_id_response_code on authorization (cost=0.57..724.31 rows=214 width=8) (actual time=0.018..3.038 rows=3623 loops=1)
Index Cond: ((card_holder_id = XXXX) AND (response_code = '00'::text))
-> Index Scan using ix_clearing_card_holder_id on clearing (cost=0.56..822.55 rows=260 width=7) (actual time=0.017..3.024 rows=3572 loops=1)
Index Cond: (card_holder_id = XXXX)
Planning Time: 0.308 ms
Execution Time: 13.175 ms
(15 rows)
意図したインデックスがちゃんと使われており、たいして遅くもありません。Row数は本記事執筆時点で各テーブル数千万〜数億です。またDBの総サイズは500GB程度、DBのマシンスペックは AWS RDS for PostgreSQL の db.m4.xlarge です。shared_buffers などには常識的な設定がされています。
トランザクションの総件数は億のオーダーですがインデックスが効いていてサクサク返ってきます。ただサイズが増えることによるコスト増は懸念しています。
4. データ量が増えたときの戦略
トランザクションの SUM で十分運用に耐えうることがわかりました。しかし今述べた通り、いずれは限界がきそうです。そのときどうするのかの戦略を練っておきます。将来的にはトランザクションのスナップショットをとる方式を採用するつもりでいます。他にはDB分割やスケールアップもあります。
先ほどのクエリでインデックスは効いていますが、ユーザが1年2年3年...と使うとフェッチする件数が増えます。データ転送量増加、SUMの計算コスト、単純なDB容量増加によるディスクアクセスなどによりパフォーマンスは徐々に悪化していきます。
スナップショット方式とは、次のようなテーブルを用意してトランザクションのある時点での残高の状態を記録し、この balance_snapthot テーブルに記録された残高と、それの created_at 以降のトランザクションを取得するようにしてフェッチする件数を減らす方式です。残高はこれらの結果を足し合わせて算出されます。
Table "balance_snapshot"
Column | Type | Collation | Nullable | Default
-------------------+--------------------------+-----------+----------+----------------------------------------------
id | bigint | | not null | nextval('balance_snapshot_id_seq'::regclass)
card_holder_id | bigint | | not null |
available_balance | numeric | | not null |
ledger_balance | numeric | | not null |
created_at | timestamp with time zone | | not null |
残高計算クエリも少し変更します。 WHERE 句にそれぞれのトランザクションテーブルのタイムスタンプを追加します。 card_holder_id との複合インデックスも貼ります。
SELECT COALESCE(SUM(available), 0) AS available_balance
, COALESCE(SUM(ledger), 0) AS ledger_balance
FROM (
SELECT amount AS available, amount AS ledger
FROM load
WHERE card_holder_id = $1 AND loaded_at > $2
UNION ALL
SELECT amount AS available, amount AS ledger
FROM charge_fee
WHERE card_holder_id = $1 AND collected_at > $2
UNION ALL
SELECT available_amount AS available, ledger_amount AS ledger
FROM admin_fund
WHERE card_holder_id = $1 AND executed_at > $2
UNION ALL
SELECT transaction_amount AS available, 0 AS ledger
FROM authorization
WHERE card_holder_id = $1 AND response_code = '00' AND received_at > $2
UNION ALL
SELECT available_amount AS available, ledger_amount AS ledger
FROM clearing
WHERE card_holder_id = $1 AND created_at > $2
) AS _
スナップショットテーブルとトランザクションテーブルを使った残高算出の擬似コードは次のようになります。
snapshot, found = get_latest_snapshot(card_holder_id)
if found {
available_balance, ledger_balance = get_balance(card_holder_id, snapshot.created_at)
return available_balance + snapshot.available_balance, ledger_balance + snapshot.ledger_balance
} else {
available_balance, ledger_balance = get_balance(card_holder_id, '1970-01-01 00:00:00')
return available_balance, ledger_balance
}
残高計算を行う箇所にてクエリの本数は1本増えますが、 balance_snapshot テーブルへのクエリは単純SELECTになるためたいしたコストはないと見込まれます。
4.2. スナップショット方式を採用した場合のベンチマーク
ちゃんとベンチマークを取って検証してみます。以下、ベンチマークテストの条件になります。
- pgbench を使う
- クエリは残高計算のクエリを3分間、where 句の card_holder_id をランダムに変更して実施
- それぞれのシナリオ実施前にRDS 再起動する
- RDS再起動後に一回 pgbench を流すがその結果は無視して、続く5回のpgbench試行をテスト結果とする
- 実施前に統計情報はリセットする
- RDS は本番と同スペックとして本番と同程度のデータを入れておく
pgbench は負荷クライアント用のインスタンスを建てて下記のコマンドで実行します。4並列(-c 4)で3分(-T 180)とします。
pgbench -h <host> -p <port> -U <username> -f balance.bench -r -c 4 -T 180
balance.bench は負荷を与えるシナリオが書かれたファイルで本試験では次のようにします。 \set ch random(1, 10000000) は、 ch という変数に 1から10000000のランダム値を与えるコマンドで、残高計算クエリの WHERE 句を WHERE card_holder_id = :ch としておくことで ch が毎回ランダムに選択されます。
BEGIN;
\set ch random(1, 10000000)
<残高計算クエリ>
END;
統計情報もベンチの結果として参考にします。下記クエリでキャッシュヒット率を、
SELECT relname
, round(heap_blks_hit*100/(heap_blks_hit+heap_blks_read), 2) AS heap_cache_hit_ratio
, round(idx_blks_hit*100/(idx_blks_hit+idx_blks_read), 2) AS idx_cache_hit_ratio
FROM pg_statio_user_tables
WHERE schemaname = '<schema_name>'
AND heap_blks_read > 0
ORDER BY heap_cache_hit_ratio,
relname;
下記クエリでインデックスのキャッシュヒット率をベンチマーク実施後に取得します。
SELECT relname
, indexrelname
, round(idx_blks_hit*100/(idx_blks_hit+idx_blks_read), 2) AS idx_cache_hit_ratio
FROM pg_statio_user_indexes
WHERE schemaname = '<schema_name>'
AND idx_blks_read > 0
ORDER BY idx_cache_hit_ratio,
relname;
4.3.1. スナップショット方式適用前(現在の状態)
| n |
tps(3min) |
avg (msec) |
| 1 |
418 |
6.396 |
| 2 |
422 |
6.306 |
| 3 |
422 |
6.293 |
| 4 |
427 |
6.176 |
| 5 |
437 |
5.944 |
relname | heap_cache_hit_ratio | idx_cache_hit_ratio
------------------------+----------------------+---------------------
authorization | 8.00 | 93.00
clearing | 10.00 | 94.00
admin_fund | 30.00 | 99.00
charge_fee | 30.00 | 99.00
load | 31.00 | 94.00
relname | indexrelname | idx_cache_hit_ratio
------------------------+---------------------------------------------------+---------------------
authorization | ix_authorization_card_holder_id_response_code | 93.00
load | ix_load_card_holder_id | 94.00
clearing | ix_clearing_card_holder_id | 94.00
admin_fund | ix_admin_fund_card_holder_id | 99.00
charge_fee | ix_charge_fee_card_holder_id | 99.00
12 (1秒以上のクエリ発生数)
4.3.2. スナップショット方式適用後
| n |
tps(3min) |
avg (msec) |
| 1 |
717 |
2.406 |
| 2 |
734 |
2.287 |
| 3 |
743 |
2.208 |
| 4 |
750 |
2.163 |
| 5 |
752 |
2.142 |
relname | heap_cache_hit_ratio | idx_cache_hit_ratio
------------------------+----------------------+---------------------
authorization | 54.00 | 96.00
clearing | 65.00 | 97.00
charge_fee | 92.00 | 99.00
load | 94.00 | 98.00
relname | indexrelname | idx_cache_hit_ratio
------------------------+--------------------------------------------------------------+---------------------
authorization | ix_authorization_card_holder_id_response_code_received_at | 96.00
clearing | ix_clearing_card_holder_id_created_at | 97.00
load | ix_load_card_holder_id_loaded_at | 98.00
admin_fund | ix_admin_fund_card_holder_id_executed_at | 99.00
charge_fee | ix_charge_fee_card_holder_id_collected_at | 99.00
6 (1秒以上のクエリ発生数)
スナップショット方式を採用しつつインデックスを適切に貼ることでパフォーマンス、キャッシュヒット率とも改善が得られました。今後パフォーマンスが悪化するようであれば解の一つとなりえることを数値で示すことができたと言えます。ちなみに PostgreSQL の shared_buffers などのパラメータを変更したベンチも走らせましたが、このケースにおいては shared_buffers の変更は特に効果が得られず、 RDS のデフォルト値である物理メモリの 25% 程度(PostgreSQL 公式の推奨値でもある)がもっともパフォーマンスが良かったです。
現在のキャッシュヒット率が思ったより低いのでさっさとスナップショット方式にしてしまうのがいいかもしれません。今のところ致命的なユーザ影響は出ていませんが...。スケールアップもそろそろしてもいいかもしれません。
5. まとめ
- 残高を履歴のみで表現する方式をとっているがクエリはサクサク返ってきます
- クエリのコストは雰囲気で判断せずにオプティマイザに聞きましょう
- DB運用の戦略を練っておきましょう
- 戦略の判断も雰囲気で行うのではなくベンチマークをとるなど数字で判断しましょう
6. 最後に
仮に本記事が読まれた場合、同意が得られるかもしれませんし反論があるかもしれません。みなさんはどう考えますか?カンムではそういう考え方もあるな、ではこういう考え方はどうか?と議論できる人が合っている気がします。
会社のブログに記事を書くと言うことは最後にこれを書かなければなりません。採用しています↓
kanmu.co.jp
おわり