KanmuでPoolを開発しているhataです。最近、ロボット掃除機を買いました。ロボと猫がじゃれている景色はいいですね。 今回はGoのユニットテストの並行化についての記事です。
TL;DR
Goのテストは、並行化することでテスト実行時間の短縮やテスト対象の脆弱性の発見などのメリットがある
基本的にはそのままでも最適化されているが、テストコードに
t.parallelを記述することでよりきめ細やかな最適化を施すことができるただし、一定規模以上のアプリケーションへの導入・運用は大変
テストコードを一気に並行化するtparagenというツールや、並行化忘れを防ぐ静的解析ツールがあり、これらを使うことで無理なくテスト並行化の導入・運用ができる
はじめに
ユニットテスト並行化とは
本記事では、「並行」「並列」という用語を使用します。本記事におけるこれらの用語を定義します。
並行:複数の処理を独立に実行できる構成のこと
並列:複数の処理を同時に実行すること
本記事のタイトルにもある「ユニットテスト並行化」は、「個々のテストを独立に実行できる構成にすること」と言い換えることができます。
記事で紹介するGoの標準パッケージtestingにはt.Parallel・-parallelというメソッド・機能があります。これらは用語の定義とは別として、本記事では固有名詞として扱います。
この記事の内容・目的
この記事の目的は、Go言語でのユニットテストの並行化を無理なく導入し、運用するための参考情報を提供することです。ゴールーチンやチャネルなど、並行・並列周りの詳細な深掘りは本記事では行いません。ご了承ください。この記事を最後まで読むことで、Go言語におけるユニットテストの並行化に関する理解が深まり、開発プロセスの効率化や品質向上につながることを期待しています。
読者は、Goである程度ユニットテストを書いてきた経験がある方を対象としています。
テスト並行化のメリット
テスト並行化は、開発プロセスにおいて重要な役割を果たします。その主なメリットは以下が考えられます。
テスト時間の短縮: テストを並行化することで、並列実行時に全体のテスト実行時間が大幅に短縮される可能性があります。例えば10分かかるテストが4つある場合、そのままでは40分かかりますが、並行化することで10分に短縮できるかもしれません。
システムリソースの効率的な利用: 最近のコンピュータは複数のコアを持つプロセッサを搭載しています。テストを並行化することで、これらのコアを同時に利用し、システムリソースを最大限に活用することが見込めます。これにより、テスト実行時のパフォーマンスが向上し、テスト実行時間がさらに短縮されます。
テストの信頼性向上: 並行化は、テストコードとテスト対象がマルチコア環境でうまく動作することを保証します。これは、特にデッドロックや競合状態といった並列実行時の問題を検出するのに有用です。カンムのアプリケーションは決済領域に関わるため、ユーザーのお金を保護する点でこの観点は特に重要と考えています。
CI/CDパイプラインの最適化: 例として「テストの後にLintを走らせ、その後にデプロイ...」といった一連のワークフローが組まれている場合は、最初のテスト実行時間がボトルネックとなっています。テストを並行化することによって、テストの部分をさらにいくつかのタスク・ジョブに分割するなどの最適化が可能となり、開発者が新機能をより迅速にリリースできるようになります。
以上のように、テストの並行化は開発プロセスの効率化や品質向上に寄与し、開発チームの生産性をより高めることができます。
並行化に伴う課題
テストの並行化は多くのメリットがある一方で、導入や運用において様々な課題も存在します。以下に、自分が体験した主な課題をいくつか挙げます。
一定規模以上のアプリケーションのテスト対応: 中〜大規模なアプリケーションでは、往々にして多くのテストケースが存在(テストケースが100個〜)し、それらをすべて並行化することは手間がかかる場合があります。また、テスト対象がグローバルな変数を参照していたり、テスト順序に依存している場合があり、テストケース間で共有されるリソースや依存関係の管理も複雑になりがちです。これらの問題を解決するためには、並行化する前にテスト対象のコードのリファクタリングや、テストコード設計の見直しが必要となります。
並行化による新たなバグの発生: テストを並行化すると、新たにマルチコア環境に関連した問題が発生する可能性があります。デッドロックや競合状態は並列実行特有の問題であり、それらを解決するためにはテストコードの設計や実装を再考する必要があります。具体的には、テストケースを隔離する・共有リソースへのアクセスを同期するなどの見直しが必要です。
データベース接続テストの並行化: データベース接続テストを並行に実行する場合、テストケース間でのデータ競合を避けるために、各テストケースが独立したデータベース接続を持つことが重要です。このような独立性を確保するためには、テストデータの準備やクリーンアップの方法を見直す・データベーストランザクションの扱いを改善するなどの工夫が必要となります。
これらの課題に対処するためには、適切なツールの採用・テスト設計方針を策定することが必要です。
testingパッケージの概要
ここでは、Go言語でのユニットテスト並行化に必要な標準パッケージtestingの概要を説明します。
Goの標準パッケージ
Go言語はそのデザインの中心にテストを位置づけています。これを反映して、Goの標準ライブラリにはtestingというパッケージが含まれています。これはユニットテスト・ベンチマークテストなど、Go言語でテストを書くための基本的なツールセットを提供しています。
並行実行のサポート
testingパッケージにはテストの並列実行をサポートする機能を提供しています。ここでは、テストを実行するgo testコマンドで指定できる、以下の2つのオプションについて説明します。
パッケージごとのテストの並行実行をサポートする
-pオプションパッケージ内のテストを並行実行をサポートする
-parallelオプション
これらは全く異なるオプションです。よく誤解されますが、-pオプションは-parallelオプションの短縮系ではありません。
-pオプション
go help buildで出力される-pオプションの説明は以下になります。
-p n
the number of programs, such as build commands or
test binaries, that can be run in parallel.
The default is GOMAXPROCS, normally the number of CPUs available.
整理すると、以下のようになります。
ビルドコマンドやテストバイナリなど、並列実行できるプログラムの数を指定するオプション。
デフォルトは論理CPUの数。
デフォルトでは論理CPUの数(=GOMAXPRCSのデフォルト値)に設定されているため、マルチコアのマシン上で動作させれば、パッケージ単位でテストが並列に実行されます。例えばルート配下にhogeパッケージとfugaパッケージの2つが存在する場合、
go test ./...
と実行すると、hogeパッケージとfugaパッケージのテストは別々のプロセスで実行されます。
-parallelオプション
go help testflagで出力される-parallelの説明です。
-parallel n
Allow parallel execution of test functions that call t.Parallel, and
fuzz targets that call t.Parallel when running the seed corpus.
The value of this flag is the maximum number of tests to run
simultaneously.
While fuzzing, the value of this flag is the maximum number of
subprocesses that may call the fuzz function simultaneously, regardless of
whether T.Parallel is called.
By default, -parallel is set to the value of GOMAXPROCS.
Setting -parallel to values higher than GOMAXPROCS may cause degraded
performance due to CPU contention, especially when fuzzing.
Note that -parallel only applies within a single test binary.
The 'go test' command may run tests for different packages
in parallel as well, according to the setting of the -p flag
(see 'go help build').
整理すると、以下のようになります。
- t.Parallelを呼び出すテスト関数を同時に実行する数の最大値を指定するオプション。
デフォルトは論理CPUの数。
1つのテストバイナリ内でのみ適用される。
このオプションの対象となるのは、t.Parallelを呼び出しているテストケースのみです。つまり、-pオプションとは違い、こちらは開発者が対応しなければなりません。
使用方法
ここでは、先述したgo testコマンドの2つのオプション-p・-parallelについて説明します。
-pオプション
-pオプションは、テストコードに手を加える必要はありません。また、デフォルトでマシンの論理CPUの数に設定されているため、基本的に指定しなくても良いです。
意図的に制限する場合は、以下のようになります。
go test -p=1 ./...
-parallelオプション
-parallelオプションはpオプションと同じく、デフォルトでマシンの論理CPUの数に設定されています。
こちらは、対象のテスト関数にt.Parallelを記述する必要があります。
例1:サブテストなし
func TestXXX(t *testing.T) {
t.Parallel()
...
}
テストケースがサブテスト化されている場合は、メインテスト・サブテスト双方にt.Parallelを埋め込みます。
例2:サブテストあり
func TestXXX(t *testing.T) { t.Parallel() t.Run("case1", func(t *testing.T) { t.Parallel() ... }) t.Run("case2", func(t *testing.T) { t.Parallel() ... }) }
goのテストはデフォルトである程度最適化されている
-pオプションはデフォルトでマシンの論理CPU数に設定されているため、パッケージ単位での並行化は何もしなくても最適化されています。パッケージは通常、独立した機能を提供する単位として設計されるため、テストの文脈でもこのような設計になっているのでしょう。このような設計は、JavaScriptのテストフレームワークであるJestでも見られます。
一方、-parallelの方は明示的に開発者がテストコード内にt.Parallelを仕込まないと最適化されません。テストケースの性質と要件を考慮して適切な並列化戦略を選択することが重要ですが、私はできるだけきめ細やかに並行化することを推奨しています。テスト時間短縮のメリットだけでなく、テストコードとテスト対象がマルチコア環境でうまく動作することを保証してくれるためです。
テスト並行化に伴う課題
テスト並行化には多くのメリットがある一方、その導入と運用にはいくつか課題があります。並行・並列が関わる性質上、特殊なものが多いため、これらの課題は一般的なテストプロセスとは異なり、注意深く対処する必要があります。
アプリケーションの規模によるもの
先に述べた通り、パッケージ内の個別のテストケースを並行化するには、t.Parallelをテスト関数で呼び出す必要があります。個人開発のちょっとしたパッケージであればあまり問題となりませんが、商用アプリケーションのコードに導入する場合は一筋縄ではありません。単純に人力での対応が大変、という工数面での問題もありますが、特定の場合における並行化によるバグへの対処が必要になる場合もあります。
並行化によるバグへの対処
環境変数に起因するもの
テスト対象の中には、環境変数を参照するものもあるでしょう。環境変数はグローバルスコープの変数と相違ないため、テストコード内でos.Setenvで環境変数を設定した場合、意図せず他のテストケースに影響を及ぼしてしまう可能性があります。
そこで、testingパッケージはt.Setenvメソッドを提供しています。
このメソッドでセットされた環境変数は、テストケースが終了した際に破棄されます。テストで環境変数を扱う際はos.Setenvではなくこのメソッドを使用するのがベターです。
ですが、t.Setenvを呼び出していた場合同じテスト関数内でt.Parallelメソッドは呼び出すことができません。並列実行時の想定外の挙動を防ぐため、意図的にpanicを起こすようになっています。
例1:
func TestXXX(t *testing.T) { t.Parallel() t.Setenv("test", "test") // panic("testing: t.Setenv called after t.Parallel; cannot set environment variables in parallel tests") ... }
このt.Setenv・t.Parallelの組み合わせは、メインテストならメインテストごと、サブテストならサブテストごとに評価されます。以下の例ではpanicは発生しません。
例2
func TestXXX(t *testing.T) { t.Setenv("test", "test") t.Run("case1", func(t *testing.T) { t.Parallel() ... }) }
よってテスト対象が環境変数に依存するようなコードになっていた場合、並行化前に以下のことに注意する必要があります。
os.Setenvを使用していないか同じテストレベルで
t.Setenvとt.Parallelを同時に使用していないか
テーブル駆動テストでのクロージャに起因するもの
Go言語では、テストケースの入力値と期待値を分かりやすくする方法として、Table Driven Test(テーブル駆動テスト3)が推奨されています。このテーブル駆動テストと並行化を組み合わせた際のよくあるバグとして、俗に言うtt := tt忘れがあります。
以下の挙動を引き起こす問題です。
- テーブル駆動テストにおいて、サブテスト関数内でループ変数を再定義せずに
t.Parallelを呼び出すだけだと、ループ最後のテストケースしかテストされない
具体的な例を示します。以下の例では、name: "test 3"のテストケースしか実際には実行されません。
例1
func TestXXX(t *testing.T) { tests := []struct { name string arg string want bool }{ {name: "test 1", arg: "arg1", want: true}, {name: "test 2", arg: "arg2", want: false}, {name: "test 3", arg: "arg3", want: true}, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { t.Parallel() if got := XXX(tt.arg); got != tt.want { ... } }) } }
この挙動を解決するには、以下のように、ループ変数を再定義します。
for _, tt := range tests {
+ tt := tt
t.Run(tt.name, func(t *testing.T) {
t.Parallel()
if got := XXX(tt.arg); got != tt.want {
...
}
})
}
このバグは非常に見つけにくいです。テストケースが全てパスする場合、テスト結果の詳細をチェックしていなければ、最後のケースしかテストされていないことに気づけません。go1.20からはgo vetにこの間違いを未然にチェックする機能が組み込まれました。テーブル駆動テストを並行化する際にはgo vetによる静的解析を有効化しておきましょう。
この問題についての詳細は、別途記事にまとめています。こちらも合わせて参考にしてください。
他の方が書かれたこちらの記事もとても参考となります。
導入・運用は難しい
Goで書かれた比較的中〜大規模アプリケーションのテストを並行化させるには、環境変数やテーブル駆動テストの落とし穴に注意しながら、各テストケースに、t.Parallelを埋め込んでいく作業が必要となります。
しかし、それは人力でやるには非常に手間がかかるばかりか、間違いや見落としが発生しやすい作業です。特に大規模なコードベースでは、既存のテストケースが数百まで及ぶ場合があり、すべてにt.Parallelを追加するのは現実的ではありません。
加えて、新たにテストを追加する際にも同じ問題が発生します。新しいテストを書く際に、開発者がt.Parallelを忘れてしまったり、他のテストケースに影響を及ぼす可能性がああった場合、それを見つけ出すのは困難です。
データベース接続テストの並行化
データベースに接続するテストの並行化は、特に注意が必要です。テストケース間でデータベースの状態が共有されるため、一つのテストケースがデータベースの状態を変更すると、それが他のテストケースに影響を及ぼす可能性があります。例えば、同じレコードに対する更新操作を複数のテストケースで行うと、実行結果が他のテストケースの動作に依存することになります。
独立したテスト環境の構築
これらの問題を解決する一つのアプローチは、各テストケースに対して独立したデータベース環境を提供することです。例えば、各テストケースで使用するデータベーススキーマを独立させるか、または各テストケースが使用するデータセットを分離するなどです。こうすることで、一つのテストケースがデータベースの状態を変更しても、他に影響を及ぼすことがなくなります。
しかし、このアプローチには注意が必要です。テスト実行前後でデータベーススキーマをセットアップ・クリーンアップする必要があります。うまく工夫しないと、このプロセスは多くの時間とリソースを消費するため、大規模なコードベースでは注意深く管理する必要があります。また、このプロセスは自動化されるべきであり、それを実現するためには適切なツールと運用が必要です。
無理なく導入するためのツールと事例紹介
さて、ここまでGoにおけるテスト並行化の導入・運用のメリットや課題について紹介しました。 ここからは、先ほど説明したテスト並行化に伴う諸課題について、私の経験をもとに解決策の一例を紹介します。
Goのテストコードを一気に並行動作できるようにするツール「tparagen」
https://github.com/sho-hata/tparagen
この「tparagen」は、Goのテストコードを静的に解析し、可能な限りt.Parallel()を適切な場所に自動挿入するGo製のツールです。数百個のテスト関数が対象であっても一瞬で並行化できるため、人力でチマチマt.Parallelを埋め込む必要がありません。そのため、ある程度規模のあるコードベースにも、無理なくテストを並行化することができます。
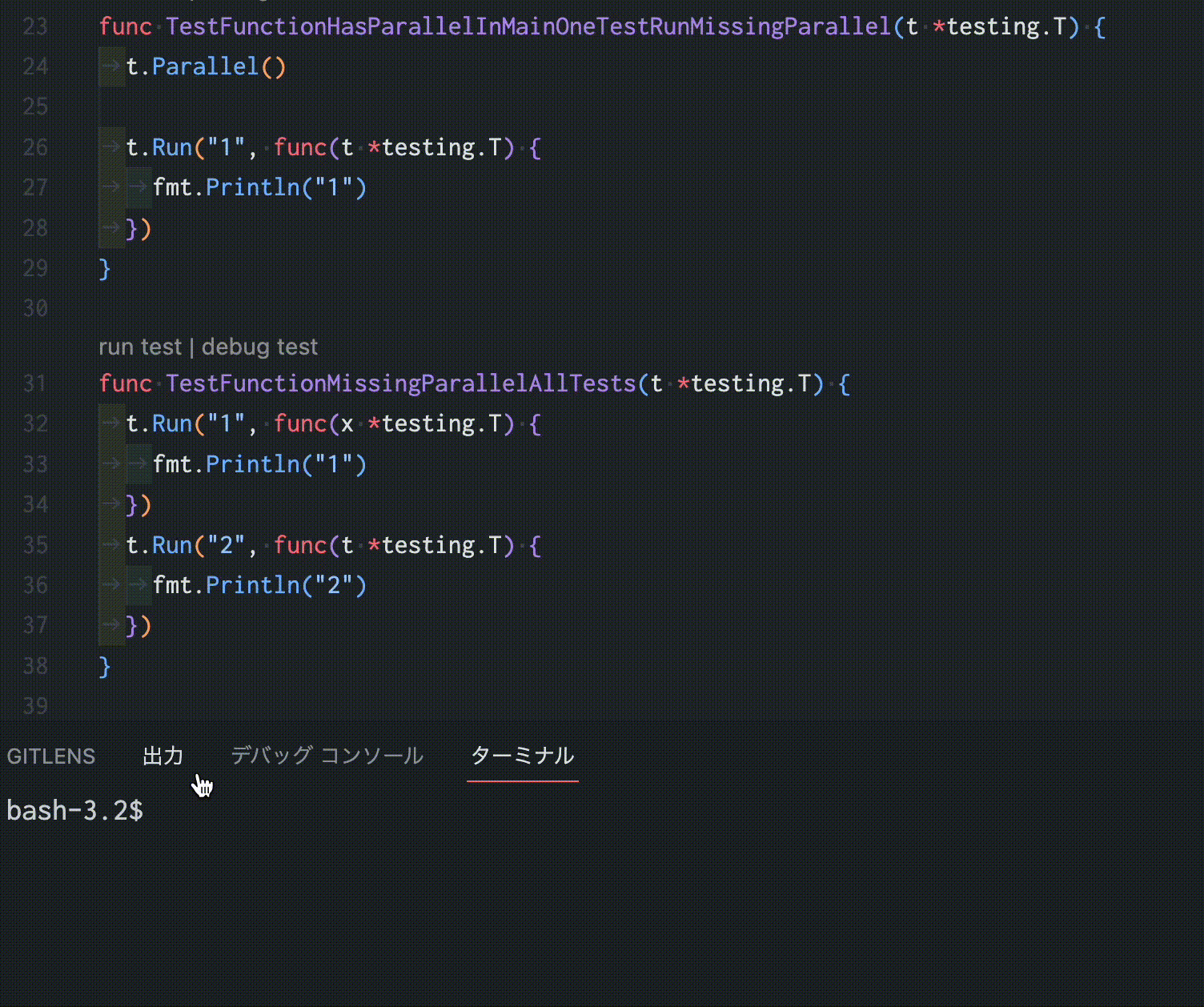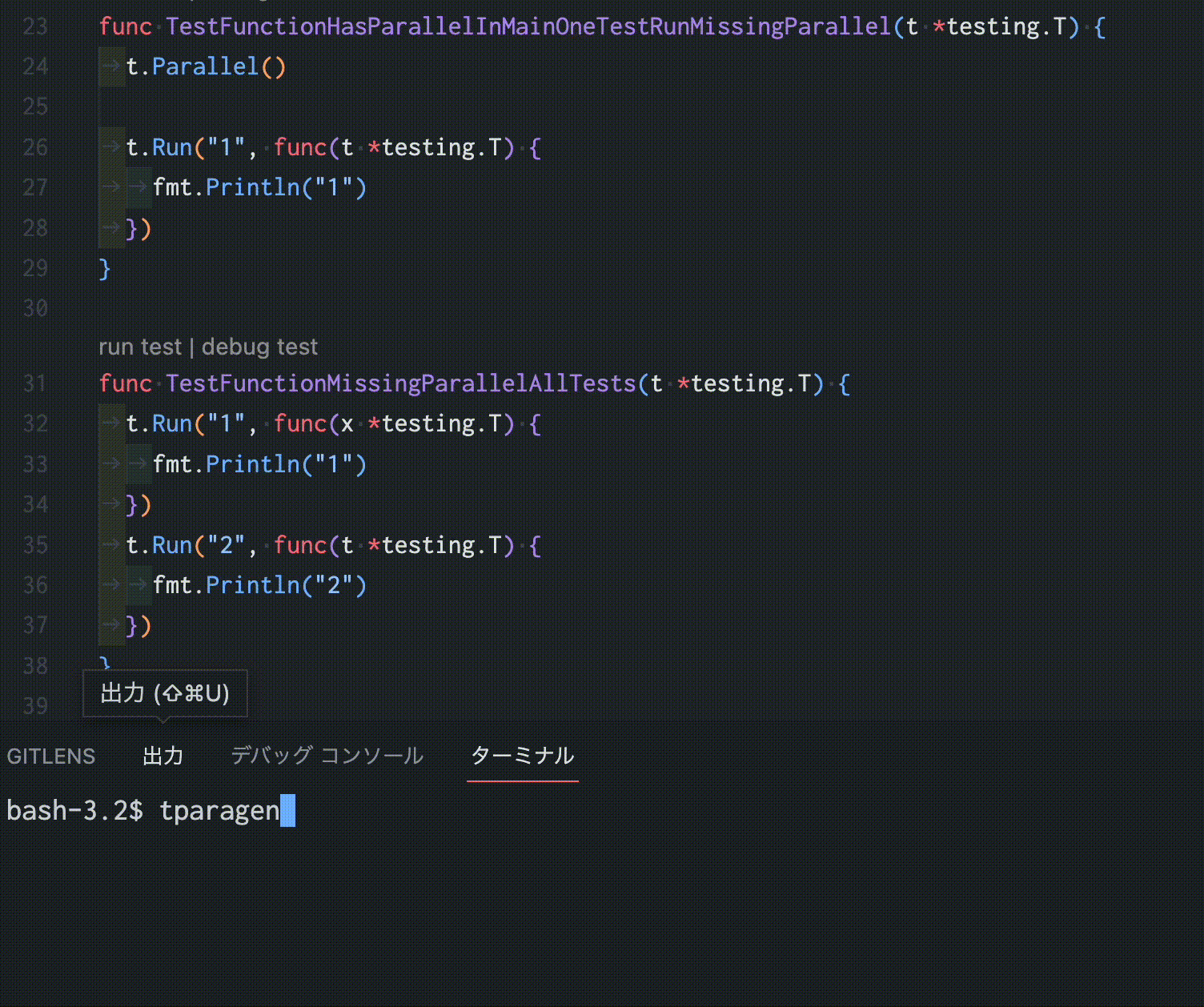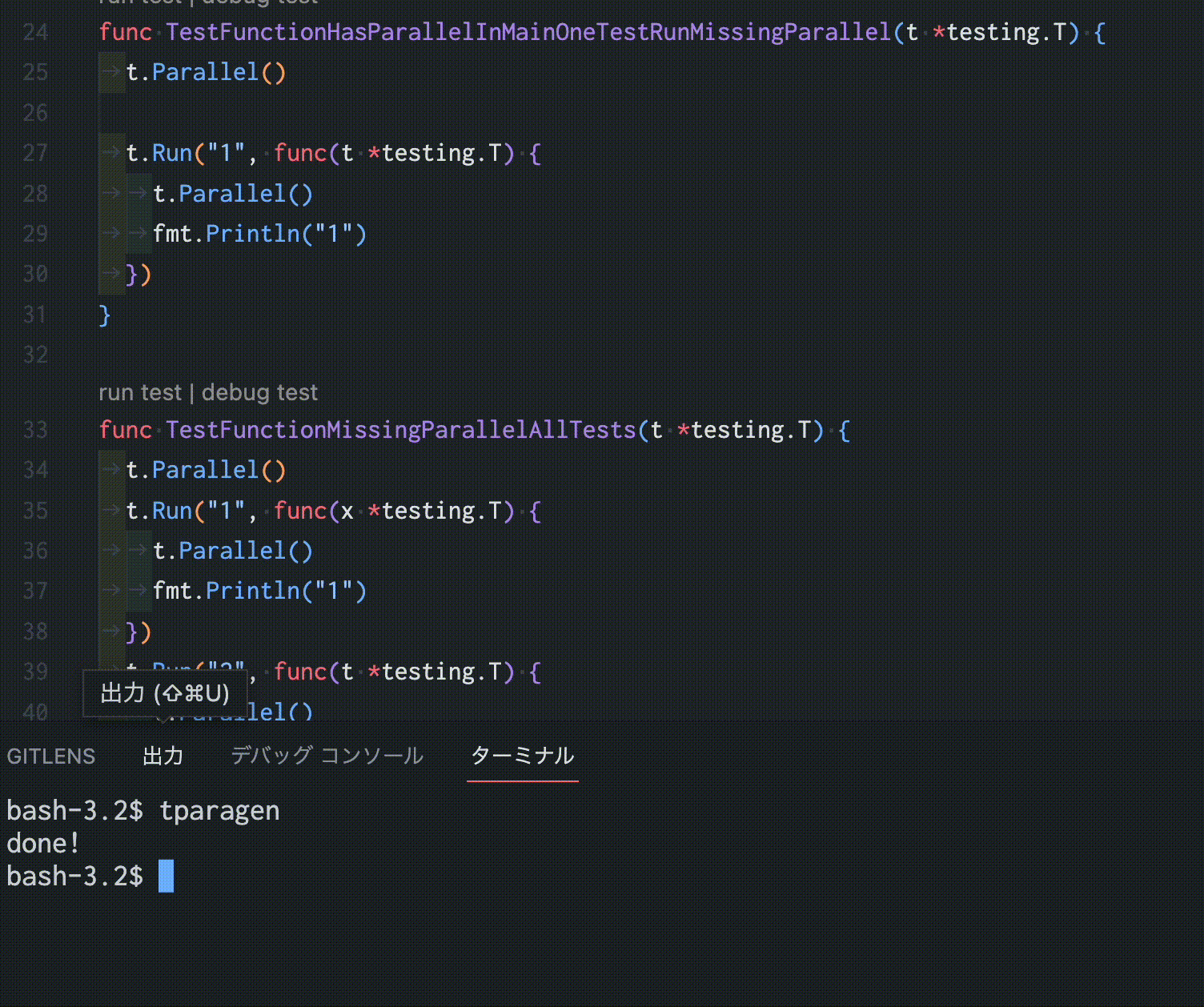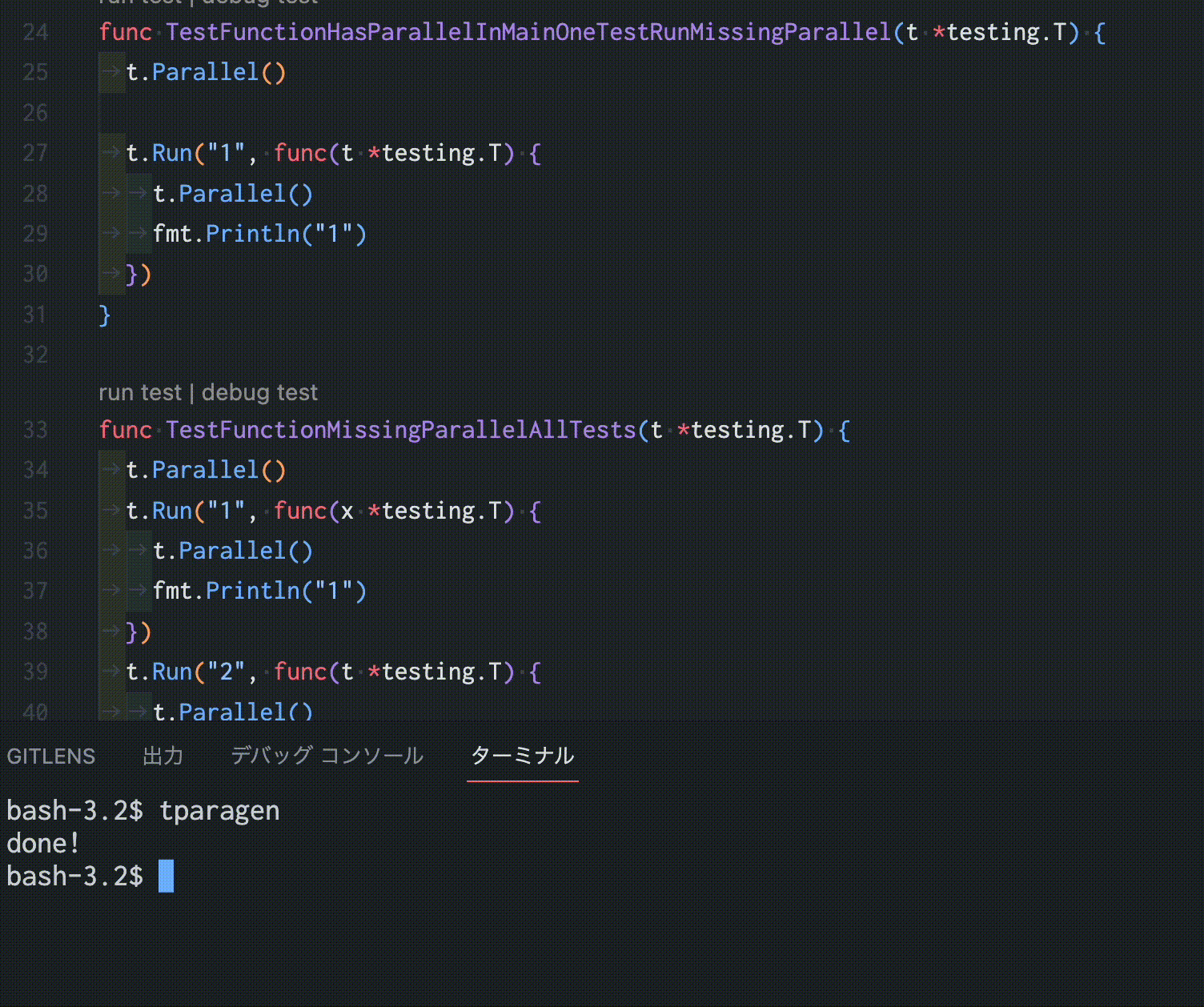
また、先に述べた問題を考慮した上でこのツールが作成されているため、安全にテストコードを並行化できます。
例えば、t.Setenvとt.Parallelが同時に呼び出されるとpanicする問題の対応策として、t.Setenvを呼び出しているテストは並行化がスキップされます。さらに、メインテストはメインテスト、サブテストはサブテスト同士でチェックするため、t.Parallelの入れ忘れを防ぎ、逆に並行化してはいけないテストにt.Parallelを入れてしまうといったこともありません。
また、tt := tt忘れによるバグも事前に防ぐ仕組みが用意されています。
以下のようなtt := tt忘れによるバグを引き起こすテスト関数があった場合、サブテストにはループ変数の再定義を行いつつt.Parallel`を埋め込みます。これにより、潜在的なバグを埋め込むことなくテストを並行化することができます。
例1: tparagen実行前(並行化前)
func TestXXX(t *testing.T) { tests := []struct { ... }{ {name: "test 1", arg: "arg1", want: true}, {name: "test 2", arg: "arg2", want: false}, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { if got := XXX(tt.arg); got != tt.want { ... } }) } }
例2: tparagen実行後(並行化後)
func TestXXX(t *testing.T) {
+ t.Parallel() // 並行化
tests := []struct {
...
}{
{name: "test 1", arg: "arg1", want: true},
{name: "test 2", arg: "arg2", want: false},
}
for _, tt := range tests {
+ tt := tt // ループ変数の再定義
t.Run(tt.name, func(t *testing.T) {
+ t.Parallel() // 並行化
if got := XXX(tt.arg); got != tt.want {
...
}
})
}
}
このほかにも、いくつか機能が搭載されています。詳細はtparagenのリポジトリをご参照ください。
https://github.com/sho-hata/tparagen
また、バグ発見等のissue報告・Pull Request大歓迎です。
t.Parallelし忘れを防止する静的解析ツール
https://github.com/kunwardeep/paralleltest
https://github.com/moricho/tparallel
これらのツールは、t.Parallelを使用していないテスト関数を報告してくれます。CIやGit Hookに組み込めば、コードレビューで人間がいちいちチェックしなくても機械的に検出してくれるため、無理なくテスト並行化を運用に乗せることができます。また、場合によっては並行化したくないテストもあります。その場合はnolintディレクティブを挿入することによりチェックをスキップすることができます。
例1
func TestXXX(t *testing.T) { // ERROR "Function TestXXX missing the call to method parallel" ... }
例2:nolintでスキップする例
// nolint:tparallel,paralleltest func TestXXX(t *testing.T) {}
ちなみに、tparagenはこのnolintがあるテスト関数は並行化をスキップします。
データベース接続テストの並行化:事例紹介
並行化コードの自動挿入ツールと静的解析ツールで、テスト並行化の導入・運用の課題はクリアできました。もう一つ、データベース接続テスト並行化の課題があります。
ここからは私の所属する株式会社カンムのpool開発チームでの、テスト並行化に向けた取り組みを紹介します。データベースと接続するテストを並行化する際の参考になれば幸いです。
先に述べた通り、データベースと接続するテストを並行化するには、テストケースごとに独立した環境の構築がポイントとなります。弊チームでは、テスト時のSQLドライバとしてDATA-DOG/go-txdbをPostgreSQL用に拡張したachiku/pgtxdbというツールを使っています。
https://github.com/achiku/pgtxdb
このpgtxdb(go-txdb)はdatabase/sql.DBと互換性があるデータベースとのコネクションを作ることができるライブラリで、以下の特徴を持っています。
各コネクションで行われる全てのデータベース操作はお互いに影響せず、トランザクション内で完結する。
もしテスト対象がトランザクションイベントを利用していた場合は、モック化する
- BEGIN -> SAVEPOINT
- COMMIT -> なにもしない
- ROLLBACK -> ROLLBACK TO SAVEPOINT
この特徴を活かし、各テスト開始時に必要なデータの準備を行い、テスト終了時にレコードの変更がロールバックするような環境になっています。トランザクションは互いに独立しているため、並列実行時にも問題はありません。
pgtxdbを取り入れた後のテスト全体のライフサイクル(パッケージ単位)は以下の図のようになります。
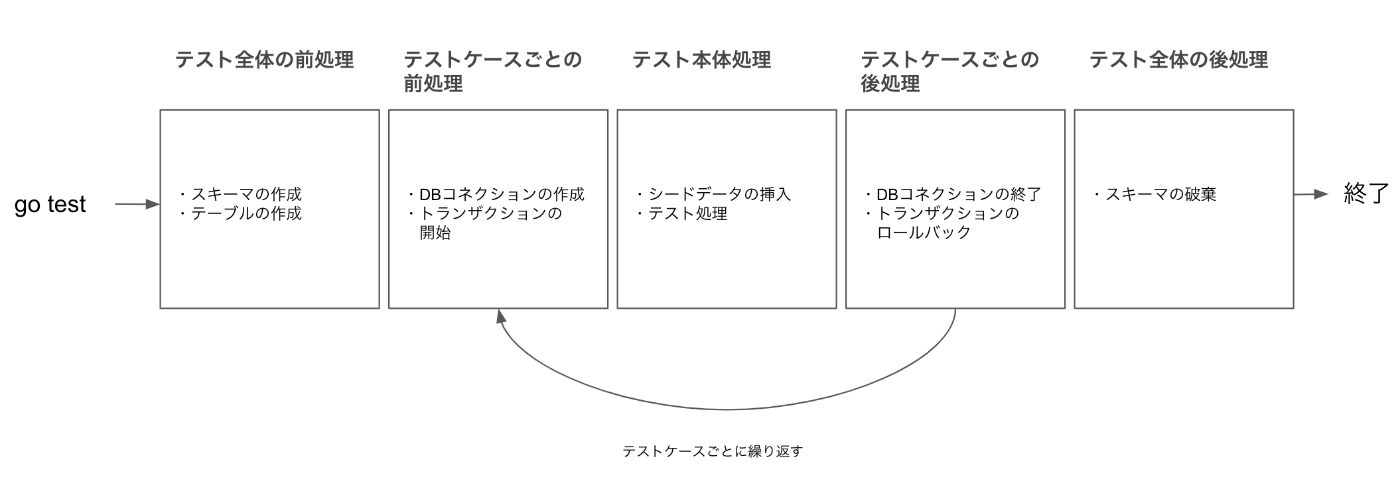
テスト全体の前後処理
テスト全体の前後処理は、func TestMain(m *testing.M)を使って実現しています。TestMainの仕様についてはtesting#Mainを参考にしてください。
大きく分けて以下のようなことをしています。 前処理
- スキーマの作成
- テーブルの作成
pgtxdbドライバの登録
後処理
- スキーマの破棄
以下は擬似コードですが、大まかはこの例のようなイメージです。m.Runの前に実行しているのが前処理、deferで実行するのが後処理です。
func TestMain(m *testing.M) { if err := createSchema(); err != nil { os.Exit(1) } if err := createTable(); err != nil { os.Exit(1) } defer dropSchema(config, schema) m.Run() }
テストケースごとの前後処理
ここでやっていることは大きく分けて以下のような処理です。
前処理
- コネクションの作成
- トランザクションの開始
後処理
テストケースごとの前後処理は、TestSetupという関数が担っています。この関数を各テストケースで呼び出すことにより、前後処理を仕込んでいます。
以下は擬似コードですが、大まかはこの例のようなイメージです。
func TestSetupTx(t *testing.T) *sql.Tx { db, err := sql.Open("txdb", uuid.New().String()) if err != nil { t.Fatal(err) } tx, err := db.Begin() if err != nil { t.Fatal(err) } t.Cleanup(func() { if err := tx.Rollback(); err != nil { } if err := db.Close(); err != nil { t.Fatal(err) } }) return tx }
ここら辺は、sql.DBを満たすインターフェース設計やpgtxdbによるトランザクションイベントのモック化などトランザクション分離を支える多くのトピックがあります。全てを紹介するとそれだけで別記事が書けるため、ここでは簡易な説明にとどめるのみとします。詳しくは弊社COO、achikuのGoCon JP 2018の登壇資料4を参考にしてください。
テスト処理
テスト本体の処理です。
- シードデータの挿入(必要に応じて)
- テスト本体処理
SQLを発行するテスト対象の関数は、必ずdatabase/sql.DBが行うDB操作を抽象化したインターフェースを引数として受け取るシグネチャになっています。ここにテストケース前処理で行ったpgtxdbのコネクションを流し込むことによって、並列実行時でも問題のないトランザクション分離環境でSQLが発行されます。
func TestGetXXX(t *testing.T) { t.Run("found", func(t *testing.T) { // 前後処理 tx := TestSetupTx(t) // シードデータ作成 d := TestCreateXXXData(t, tx) // テスト本体処理 res, err := GetXXX(tx, d.ID) assert.NoError(t, err) assert.Equal(t, u.ID, res.ID) }) }
まとめ
というわけで、Goのユニットテスト並行化についての導入・運用アプローチについて詳しく見てきましたが、いかがでしたでしょうか。 ユニットテストを並行化することで、
テスト実行時間が早くなることによるリリースサイクルの高速化
並列実行時の動作を担保することによるアプリケーションの頑健化
が期待できます。
テストコードは増えれば増えるほどテストの実行時間も増加し、開発時間が大幅に割かれる可能性があります。テスト並行化の結果がたとえ1分1秒の短縮でも、将来的には大幅な効率改善につながるでしょう。
また、ソフトウェアの頑健性向上にもテスト並行化は重要な役割を果たします。並列実行時に特有のバグは往々にして解決が難しく、本番環境にリリースしてからの発見や調査はさらに難しくなります。テスト対象のコードがマルチスレッド下の環境でバグを発生させる可能性がある場合、テストの並行化によって早期にその問題を把握できます。
ただし、テスト並行化にも課題や落とし穴が存在します。重要なのはリリースサイクルの高速化やアプリケーションの頑健化が目的であり、テスト並行化はそのための手段であるということです。自分も陥りましたが、テスト並行化を導入・運用するために人力での並行化コードの埋め込みやチェックで貴重な人的リソースを浪費するのは本末転倒です。
全てのテストを無闇に並行化するべきという主張ではありません。テスト並行化は、そのメリットとデメリットを理解し、チーム全体でその導入の是非を検討することが重要です。