カンムでCOOをしています、achikuです。
ニッチすぎて誰に話しても「?」となるが、とにかく理解できて嬉しかったSQLの話をする。
誰かにこの感動を伝えたいのでコーヒーカップに向かってクエリの説明している
— _achiku (@_achiku) February 21, 2021
話しを簡単にする為にコイントスを用いた例題で説明する。
問題
複数回のコイントスの結果(試行ID、裏が出たか表が出たか、トスした時間)を記録したデータがある。このデータを用いて試行回数t回目において何回連続で表が出たかを出力したい。なお、一度裏が出たら連続で表が出た回数は0にリセットされる。
問題を表で表現する
最終形からイメージすると、大体以下のような事がしたい。試行回数t回目において連続でhead=trueである回数を出す。とにかく時系列に並べた際に時点tにおける連続表が出た回数が欲しい。
consecutive_head: 連続で表が出た回数
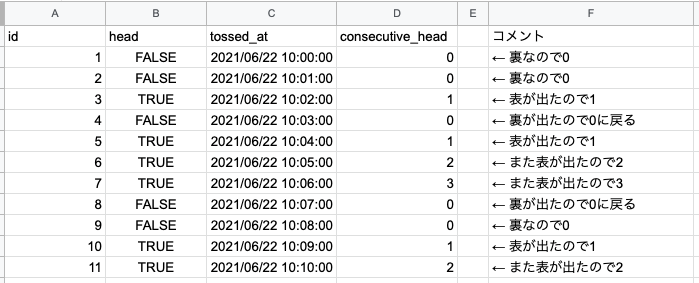
解く為の考え方
まず完成形の集合を眺める。連続で表が出た回数は裏が出たらリセットされる。つまり、「裏が出る」というレコードでパーティションを作れれば良さそうな気がする。裏が出た累積回数と定義するとちょうど良さそう。ということで、Window関数を利用して良い感じにリセット出来ないかというところに行き着く。図で表すと以下のようなイメージ。
cumulative_tail: 累積裏が出た回数
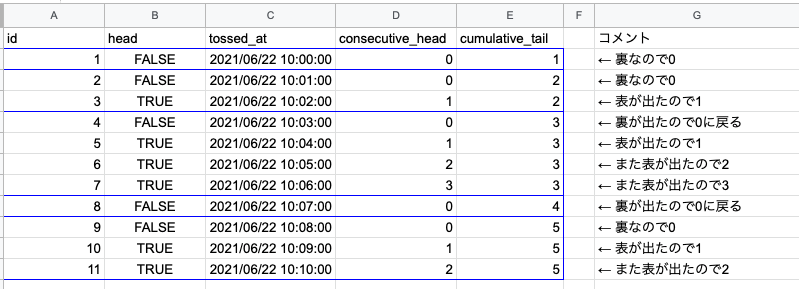
小さく作って試す
CTEで小さく作って試すとアイディアが正しいのかどうかを手を動かしながら試しながら確認していけるのでとても良い。複雑なものを小さく分けて結果の正しさを確認していく行いはプログラムを書く際にとても役に立つ。以下はPostgreSQLで書いたがBigQueryでも少し修正すればいけるはず。
with coin_toss(id, head, tossed_at) as ( values (1, FALSE, '2021/06/22 10:00:00'::timestamp) , (2, FALSE, '2021/06/22 10:01:00'::timestamp) , (3, TRUE, '2021/06/22 10:02:00'::timestamp) , (4, FALSE, '2021/06/22 10:03:00'::timestamp) , (5, TRUE, '2021/06/22 10:04:00'::timestamp) , (6, TRUE, '2021/06/22 10:05:00'::timestamp) , (7, TRUE, '2021/06/22 10:06:00'::timestamp) , (8, FALSE, '2021/06/22 10:07:00'::timestamp) , (9, FALSE, '2021/06/22 10:08:00'::timestamp) , (10, TRUE, '2021/06/22 10:09:00'::timestamp) , (11, TRUE, '2021/06/22 10:10:00'::timestamp) ) select c.id , c.head , c.tossed_at , sum(case when c.head = false then 1 else 0 end) over (order by c.id) as cumulative_tail from coin_toss as c
これで上に乗せた図の cumulative_tail が出せる事は分かった。後は cumulative_tail でパーティションを切って表が出た回数を試行順に累積していけば良い。
回答
with coin_toss(id, head, tossed_at) as ( values (1, FALSE, '2021/06/22 10:00:00'::timestamp) , (2, FALSE, '2021/06/22 10:01:00'::timestamp) , (3, TRUE, '2021/06/22 10:02:00'::timestamp) , (4, FALSE, '2021/06/22 10:03:00'::timestamp) , (5, TRUE, '2021/06/22 10:04:00'::timestamp) , (6, TRUE, '2021/06/22 10:05:00'::timestamp) , (7, TRUE, '2021/06/22 10:06:00'::timestamp) , (8, FALSE, '2021/06/22 10:07:00'::timestamp) , (9, FALSE, '2021/06/22 10:08:00'::timestamp) , (10, TRUE, '2021/06/22 10:09:00'::timestamp) , (11, TRUE, '2021/06/22 10:10:00'::timestamp) ) , coin_toss_with_cumulative_tail as ( select c.id , c.head , c.tossed_at , sum(case when c.head = false then 1 else 0 end) over (order by c.id) as cumulative_tail from coin_toss as c ) select t.id , t.head , t.tossed_at , t.cumulative_tail , sum(case when t.head = true then 1 else 0 end) over (partition by t.cumulative_tail order by t.id) as consecutive_head from coin_toss_with_cumulative_tail as t
どういう場合に使うのか
頻繁にツボから紅白の玉を取り出すことがある人達は便利に利用出来るSQLになっていると思う。それ以外にも例えばゲームを連続で何回成功したらその後n回の継続率に影響があるのか、連続何日サイトを訪れることでその後n日継続率に影響があるのか、等を調べる際にも使えるかもしれないが、ニッチな集計要件なので是非この機会にこのSQLを起点に分析を考えてみてみるのはいかがでしょう。
採用してます
「現場にある迫真の具体性を明らかにし、現状の課題を言語化/定量化し、チームの課題認識を揃える」という職を募集しています。データアナリストやマーケターと呼ばれることが多い職種なのですが、人によって定義がブレるので「現場にある迫真の具体性を明らかにし、現状の課題を言語化/定量化し、チームの課題認識を揃える」職としか言いようがないなと最近感じております。そのためにはそれぞれの専門領域はあれでも、定性調査だろうと、定量調査だろうと、効果検証だろうと、SQLを書くだろうと、Notebookを書くだろうと、なんでもやるチームです。以下を読むとやっていることがもう少し具体的になるかもしれません。
「あぁぁこのクエリ確かに面白いな!」と思ったら、achiku までお声掛けください!一緒にニッチな集計要件の話で盛り上がりましょう。







